Documentation
Azure Blob Store Connector
For a general introduction to the connector, please refer to https://www.rheininsights.com/en/connectors/azure-file-storage.php .
Azure Blob Store Configuration
The connector uses a shared access key to authenticate against the Azure Blob Store APIs. Therefore, please proceed as follows
Open https://portal.azure.com
Go to your Azure storage account deployment
Click on Security & Networking
Click on Access keys
Make a note of the account name
And click on one of the show buttons for the first or second access key
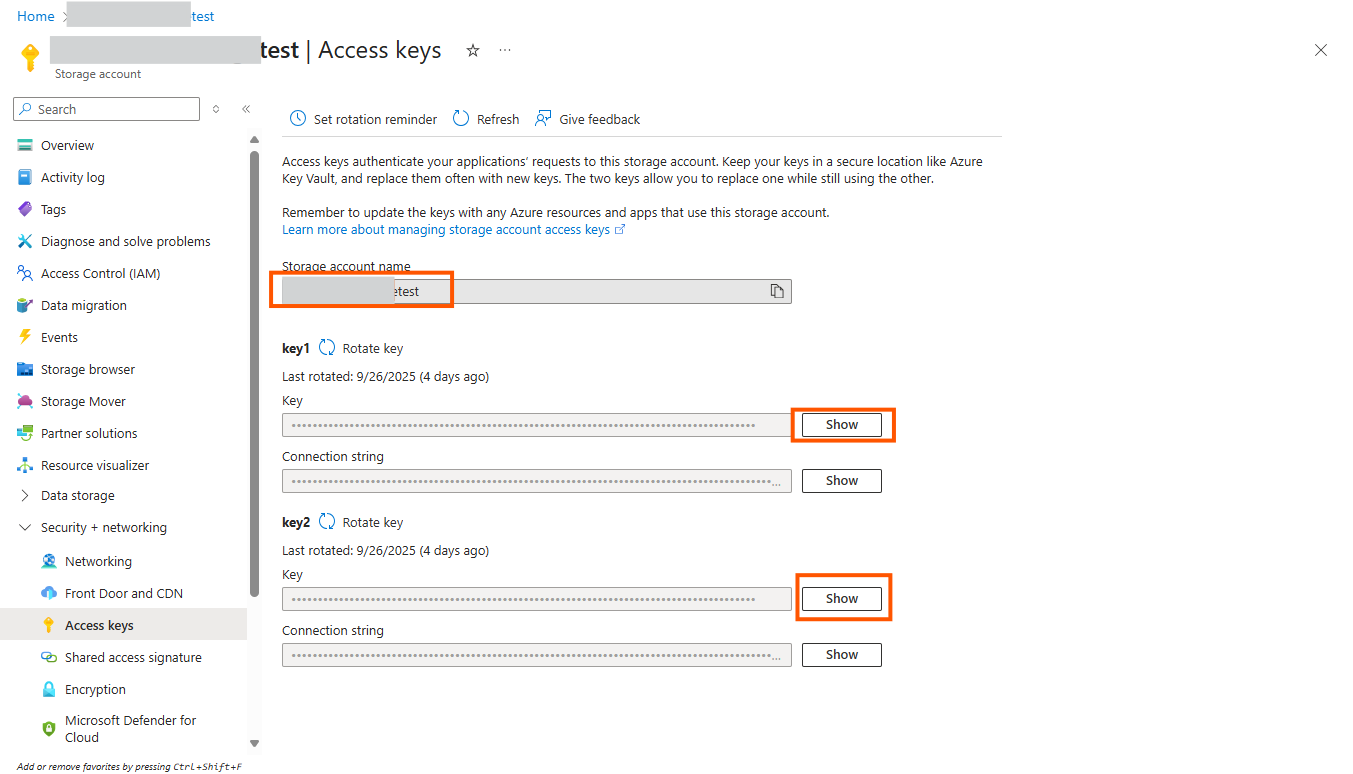
Make a note of the access key
Moreover click on Networking and make sure that the azure storage can be accessed from the machine where your Retrieval Suite deployment runs.
Content Source Configuration
The content source configuration of the connector comprises the following configuration fields.
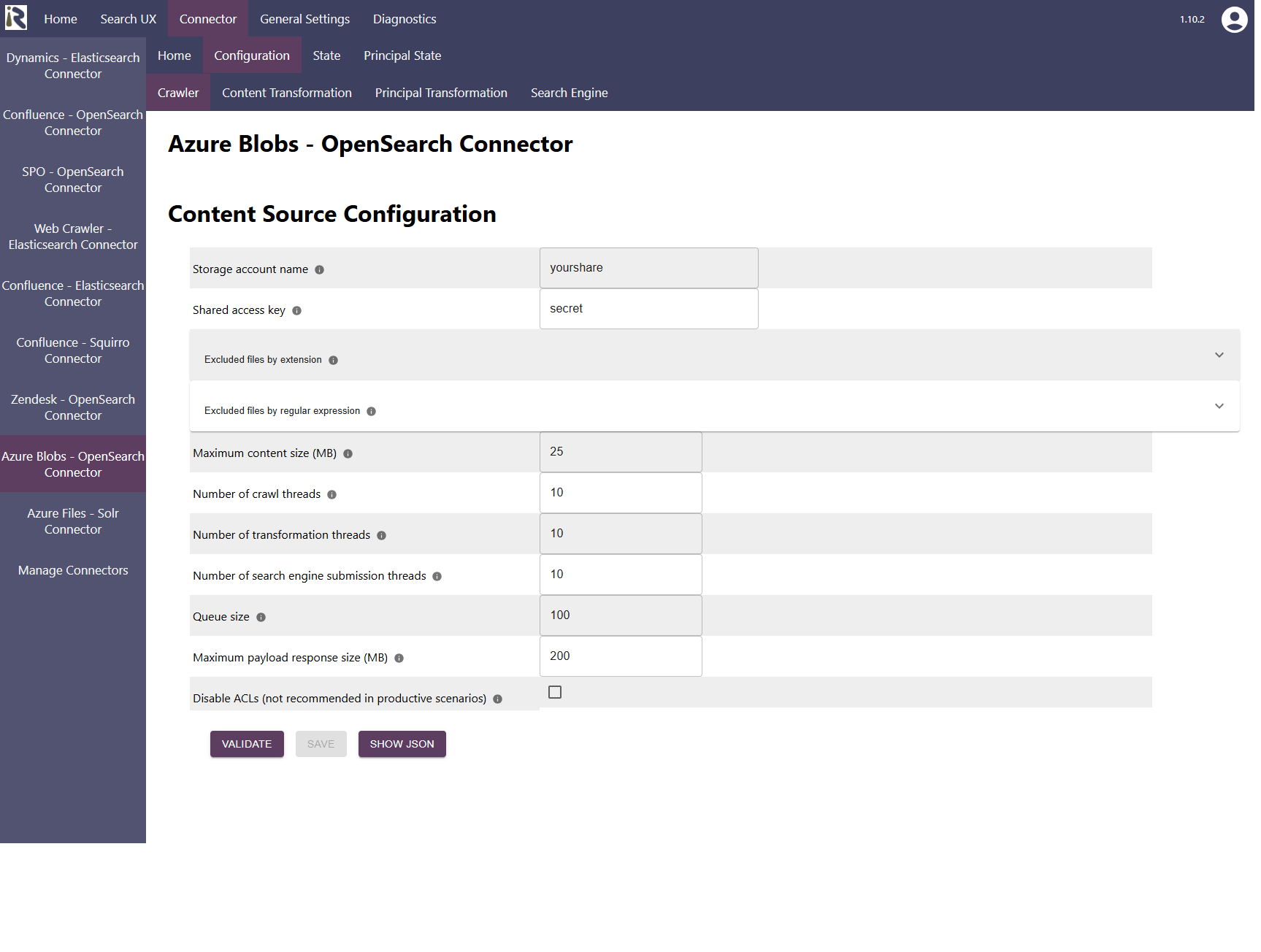
Storage account name: This is the name which you took a note for above.
Shared access key: This is one of the two access keys which we saw above
Excluded files by extension: here you can add file extensions to filter attachments which should not be sent to the search engine.
Excluded files by regular expression: here you can add directory names or file names in a list. The format can be exact file names or Java regular expressions (cf. Pattern (Java Platform SE 8 ) (oracle.com))
Please note that a change to this list will yield an incremental crawl to remove all filtered files and folders from the search index.
After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source. If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Recommended Crawl Schedules
Azure Blob Stores do not offer a change log, though they are normally relatively fast in offering document metadata. Thus, our Azure Blob Store Connector supports Full Scans and Recrawls as crawl modes. In normal operations, Full Scans will be used to keep the search index up to date.
Therefore, we recommend to configure Full Scans to run every day. For more information see Crawl Scheduling .