Documentation
- Getting Started
- Deployment

- Technical Prerequisites
- Data Privacy and Routing
- Administration
- Enterprise Search Connectors
- Managing Connectors
- Connector Home View
- Sources
- Content Transformation
- ACL Assigner
- Adjustable Text Extractor
- Data Logger
- Document Classifier
- Document Preview Generation
- Document Splitter
- Document Translation
- Html Token Remover
- Metadata Assigner
- Metadata Extractor
- Metadata Mapper
- Text Extractor
- Vectorizer and Embeddings
- LLM Specific Configurations - Content Transformers
- Security Transformation
- General Crawl Settings
- Performance Considerations
- Crawl Modes
- Crawl Scheduling
- Standard Schema
- State View
- Principal State View
- Search Experiences
- AI and Query Pipelines
- Search Engines
- MCP, Agents and Bot Integrations
- Backup and Restore Concept
- Software Updates and Upgrade
- Releases and Release Notes
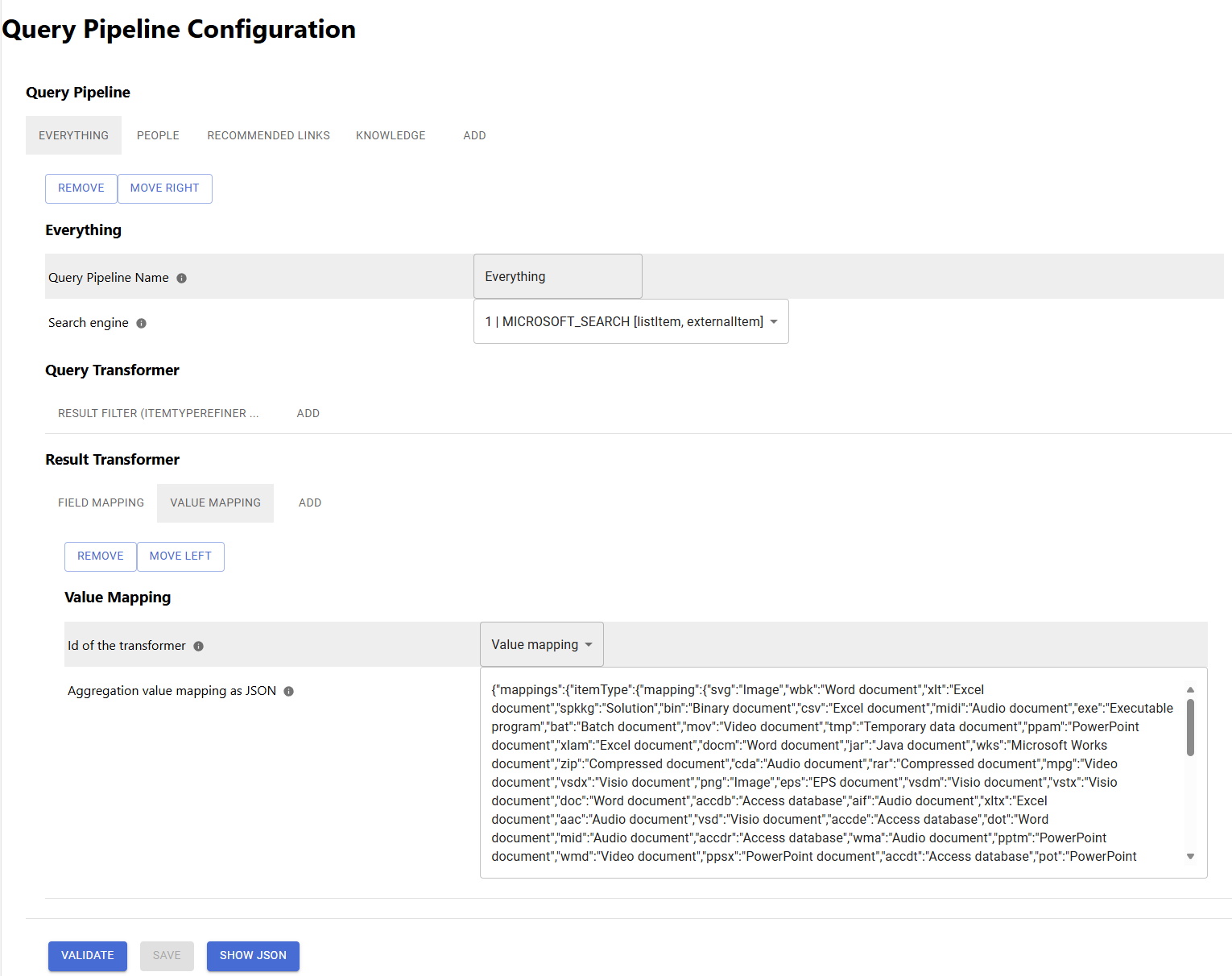
Content Transformation
Before documents become indexed, they run through the connector’s content transformation pipeline. This pipeline can be empty but you can also apply different transformation steps.
Please note that the content transformation is only executed if a document was detected as new or changed. Unchanged and deleted documents do not trigger the content transformation pipeline.
The following stages are available
Matcher
You can decide if a content transformation stage should be executed. If the list of matchers per stage is empty, the stage is executed for every indexed document.
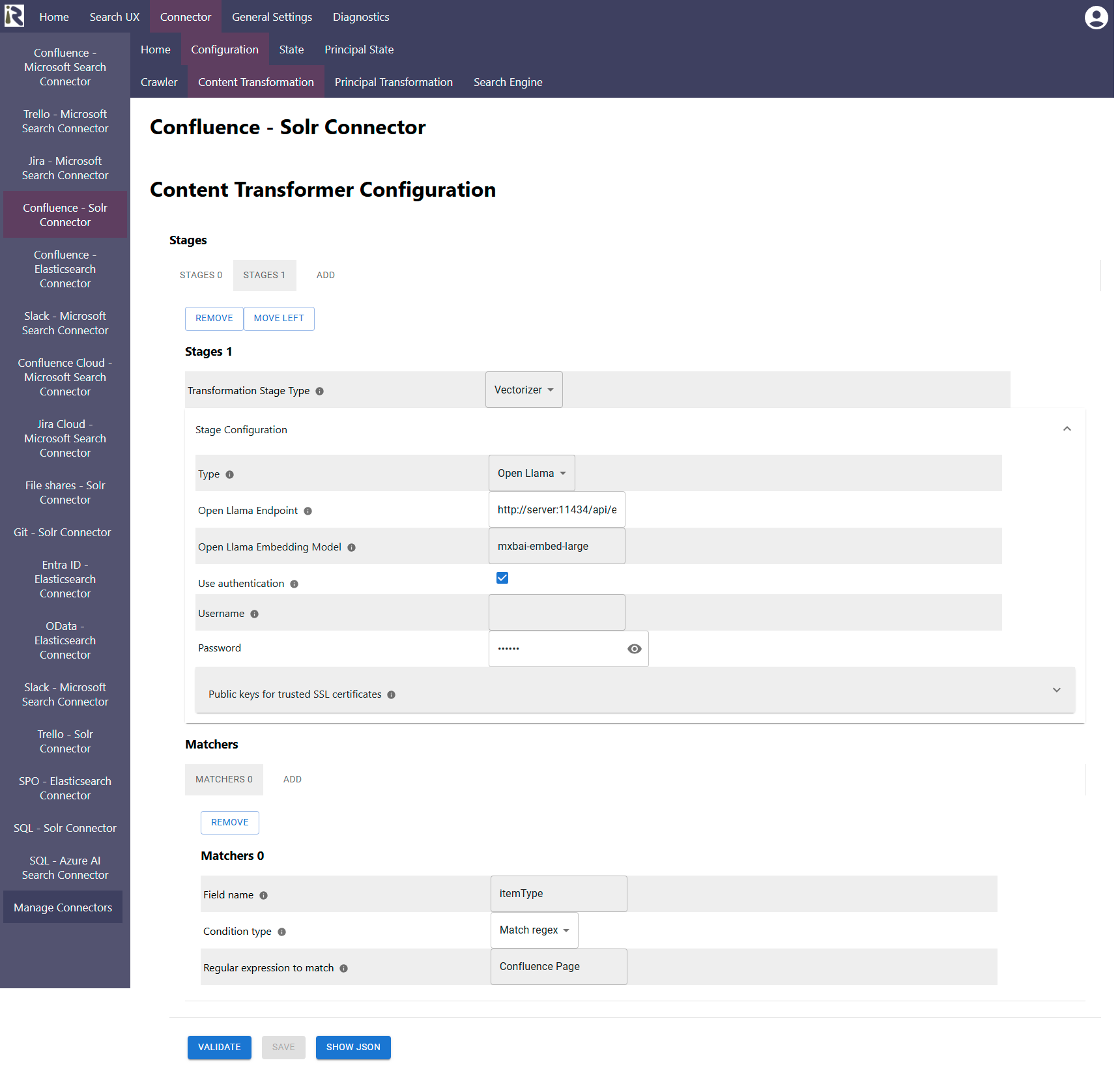
Configuration Parameters:
Field name: is the name of a document field. Please refer to the metadata displayed in State View
Condition Type:
Match regex. Here you can add a regular expression in the next field. The regular expression must be a valid Java regex format.
Match empty value. This means that the matcher matches, if the given field in 1. does not carry a value or if the value(s) are empty.
You can add multiple matchers per stage. This means that all matchers must match the document. Otherwise the stage is not executed for this document.
Debugging and Visualization
The content transformation pipeline leaves log traces. Moreover, you can see how a document got transformed within the State View . For each document, each applied stage generates one set of metadata with highlighted differences.
Execution Order
The ordering of the respective transformers in the pipeline’s configuration dialog determines the execution order of the stages. In the example below, the query is transformed as follows:
Field Mapping → Value Mapping
If you want to change the execution order, click on the respective stage, you want to move and click on move left or move right.