Documentation
Web Page Connector
For a general introduction to the connector, please refer to RheinInsights Web Pages Connector.
Our web crawler crawls entire web pages incrementally. As this is an explorative task, it uses the page links, i.e., hrefs and onclicks to find the next URLs to crawl. You can also add a sitemap.xml here.
Exactly the same URL is crawled only once. However, if you have altering Get-Parameters in an URL, the connector will ignore variations in ordering and crawl this page multiple times, i.e., as long as there are unknown permutations.
Content Source Configuration
The content source configuration of the connector comprises the following configuration fields.
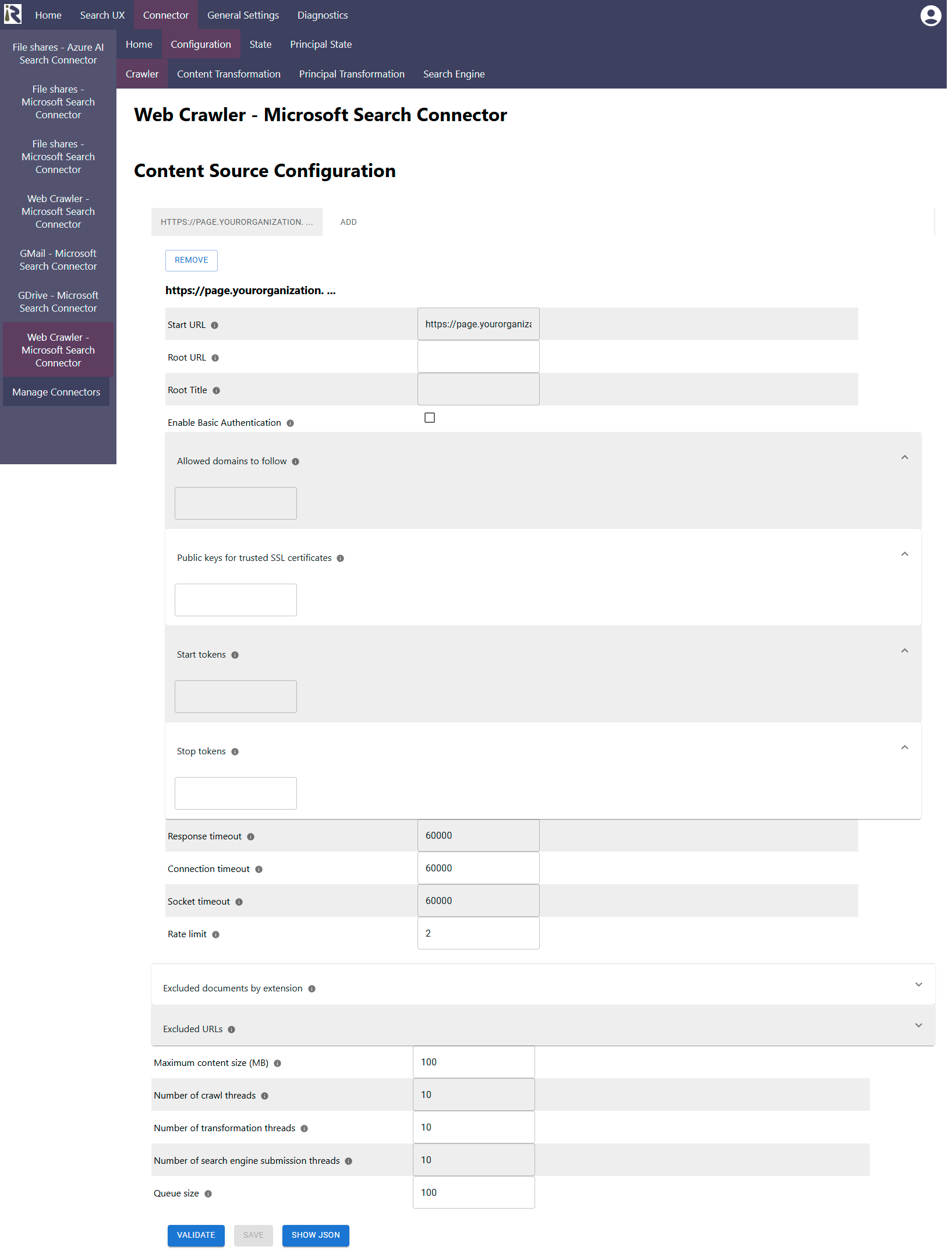
Please note that you can add multiple configurations with different entry points for web sites for one web crawler. |
|---|
Start URL: Is the initial URL this connector should crawl.
Root URL: This is the URL which will be assigned to all found pages as the rootUrl metadata. It is intended to save you from configuring a metadata assigner stage in the content transformation pipeline.
Root Totle: This is the value which will be assigned to all found pages as the rootTitle metadata. It is intended to save you from configuring a metadata assigner stage in the content transformation pipeline.
Enable basic authentication. If this is turned on, the connector uses the basic auth information, as given in the next configuration fields.
Username: is the username for authenticating against the web page.
Password: is the password used for authenticating against the web page.
Allowed domains to follow: Please add (Java) regular expressions which match the URLs the connector should crawl. If a found page URL does not match any of these regular expressions, the connector will not crawl this page and will also not use it to find the next URLs.
Public keys for SSL certificates: this configuration is needed, if you run the environment with self-signed certificates, or certificates which are not known to the Java key store.
We use a straight-forward approach to validate SSL certificates. In order to render a certificate valid, add the modulus of the public key into this text field. You can access this modulus by viewing the certificate within the browser.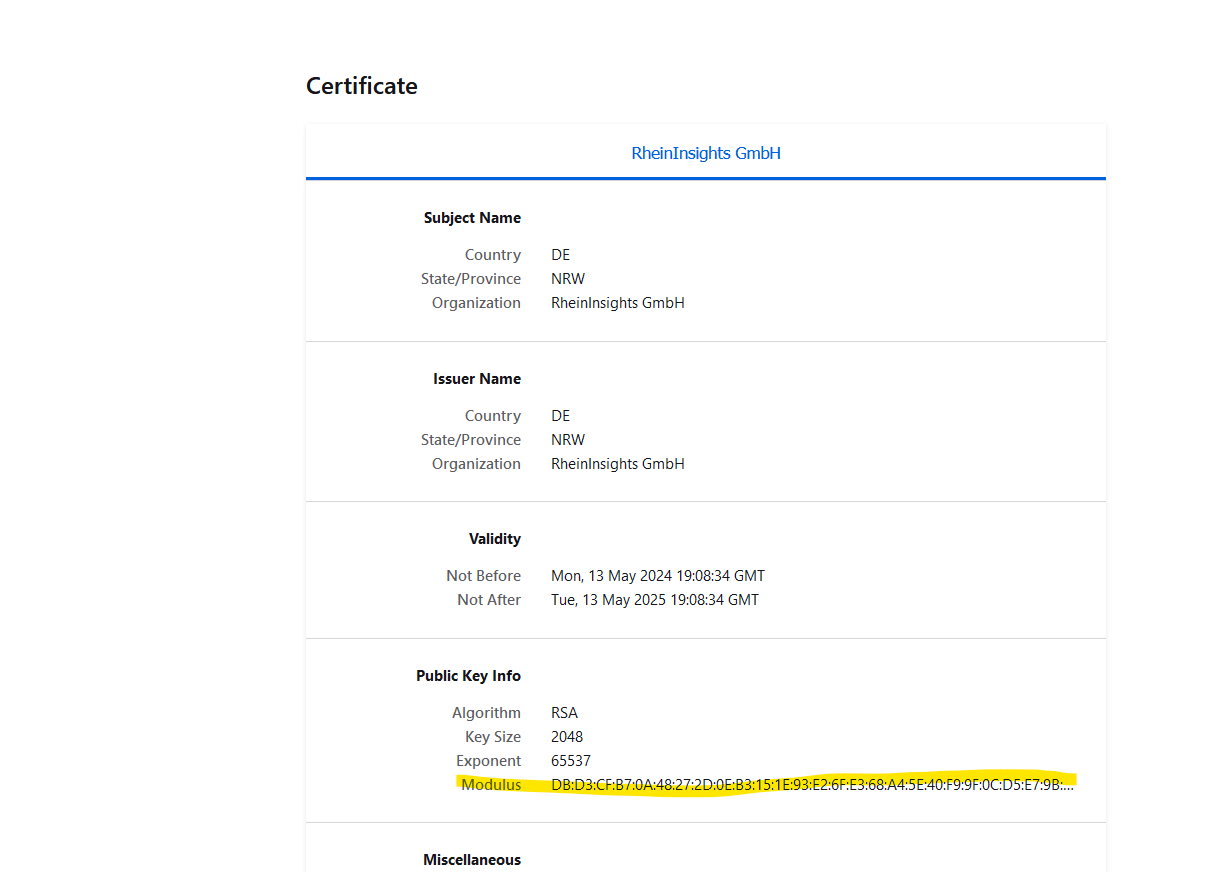
Start tokens for content extraction: fill this field with strings which the connector will use to cut out text portions, which do not wish to have indexed from your pages. This can be a string which indicates the end of your top navigation and the beginning of the page specific content.
Stop tokens for content extraction: fill this field with strings which the connector will use to cut out text portions, which do not wish to have indexed from your pages. This can be a string which indicates the beginning of your footer and the end of the page specific content.
The general settings are described at General Crawl Settings and you can leave these with its default values.
Response timeout: determines the timeout when waiting for Solr responses in milliseconds.
Connection timeout: determines the timeout when waiting for connections to Solr in milliseconds.
Socket timeout: determines the timeout when waiting for connections to Solr in milliseconds.
Rate limit: This tells the connector how many requests per second it is allowed to issue against the web page. The default value is 2 per second. The rule of thumb is that a crawler should not tear down a web page, so please be careful when increasing this parameter.
After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source. If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Recommended Crawl Schedules
Web pages do not offer a reliable change log. Thus, our Web Page Connector only supports full scans and recrawls as crawl modes. In normal operations, full scans will be used to keep the search index up to date.
The connector as such does not offer secure search. If you like to assign privileges to certain page regions, you can use an ACL Assigner ACL Assigner and assign permissions based on the url-metadata field.
We recommend to configure Full Scans to run every day. For more information see Crawl Scheduling .