Documentation
Crawl Modes
You can manually start and stop crawls from the Connector Home View, cf. Connector Home View . Furthermore, you can schedule crawls by following the steps at Crawl Scheduling .
Below, we describe the differences between the respective crawl modes.
Content Crawls
The following crawl modes fetch documents from the content source, process these in the transformation pipeline and indexes these in the search engine.
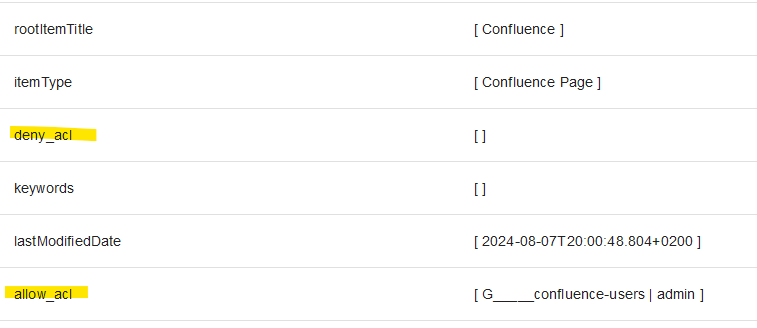
All three crawl modes are designed to always fetch the entire metadata, the document contents and access control lists (ACLs) and document security descriptors. Together with the Principal Crawls, as described below, this allows for implementing secure search with early binding security trimming. Be it for retrieval augmented generation with secure vector search or for enterprise search.
Recrawl
A recrawl is a full ingest of all content in the crawl scope. This means that changed and unchanged documents will be detected in the crawl, will be sent through the content processing and sent to the search engine for indexing. This crawl mode detects deleted documents, too, and removes these from the search index.
This crawl mode is reasonable if your search index is corrupt, you implemented changes to the index schema which need a reindexing or if you changed the content transformation pipeline significantly.
Full Scan
A full scan is a crawl which scans the entire content source. But only documents which have been changed are sent through the content transformation pipeline and sent to the search engine for indexing.
This crawl mode is a fallback to incremental crawls and should run at least once a week.
Incremental Crawl
Incremental crawls use content source APIs, such as change logs, to detect new, changed or deleted documents. This crawl mode is not available for all content sources and it might be necessary to run full scans as a fallback to detect deleted documents or changes which are not exposed through the change log.
For more information, please refer to the documentation of the respective content source connector.
Principal Crawls
For secure search, our connectors compute access control lists (ACLs) for each document. However, the connectors do not flatten these ACLs but keep group Ids in these lists, where it is reasonable.
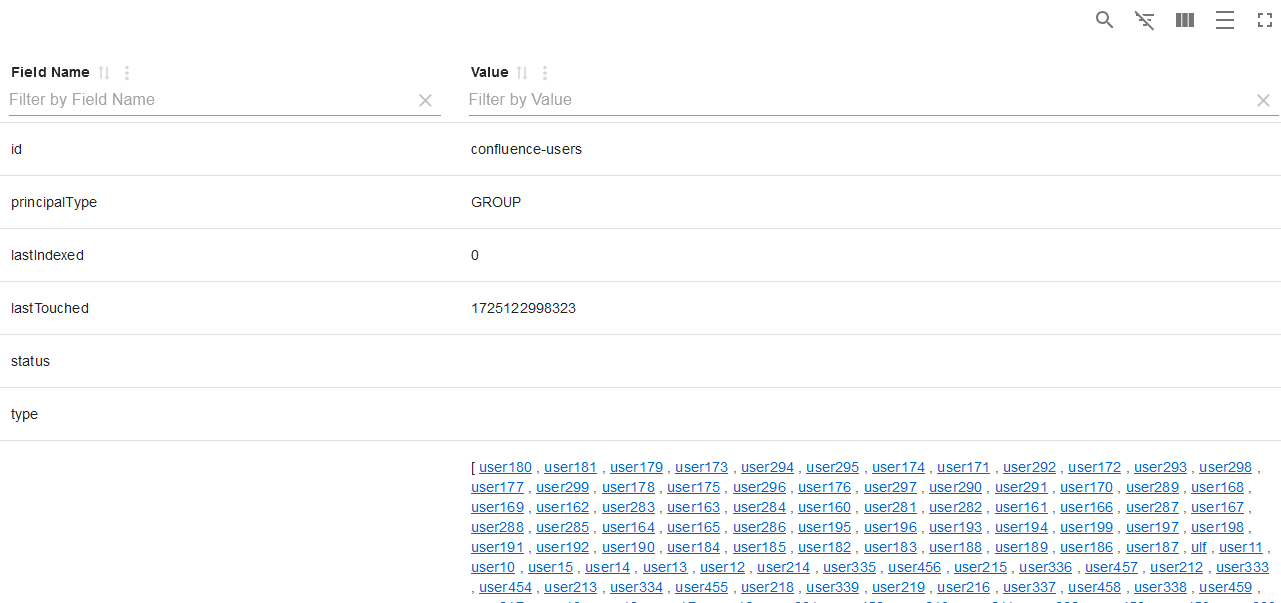
The users who relate to a group are thus fetched in the principal crawls. In such principal crawls, the connectors compute the user-group relationships and these become indexed into a separate security source within the search engine.
You can always view the current user-group relationship within the principal state view, as described at State View .
Recrawl
This crawl mode iterates over all user-group relationships of the content source. The complete set of relationships is then indexed in the configured search indexes' principal data source. This crawl mode also detects deleted users, groups and deleted user-group relationships.
This crawl mode is reasonable if your search index is corrupt, you implemented changes to the index schema (such as renaming of the source) which need a reindexing or if you changed the principal transformation pipeline significantly.
Full Scan
This is the default crawl mode for principals. It detects all changed, new and deleted user-group relationships and indexes these in the search engine.