Documentation
Microsoft SharePoint 2013, 2016, 2019 and SharePoint Server Subscription Connector
For a general introduction to the connector, please refer to RheinInsights Microsoft SharePoint Connector . This connector supports Microsoft SharePoint 2013, Microsoft SharePoint 2016, Microsoft SharePoint 2019 and Microsoft SharePoint Server Subscription.
SharePoint Configuration
Our Microsoft SharePoint Connector supports user based authentication against SharePoint and uses the REST APIs provided by your instance.
Therefore, it uses a crawl user for accessing the data. Authentication can take place via NTLM or Kerberos. We recommend that the user’s password does not expire.
Permissions
The crawl user needs to have the following permissions.
For each site collection, site or web which should be crawled, the user must have the permission to read
members of site groups
site roles
site role assignments
lists (in the crawl scope)
list items and versions
web’s change log
enumerate sub webs, if these are used in your tenant and should be crawled
This means that either you create a full read user policy on Web Application level or you assign the following role permissions to your crawl user within all sites, which should be crawled:
List Permissions
View Items, Open Items, View Versions, View Application Pages,Site Permissions
Browse Directories, Enumerate Permissions, View pages, Browse User Information, Use Remote Interfaces, Use Client Integration Features, Open
Of course, a site owner has these permissions, or you can create a custom permission level.
Active Directory
The crawl user or a separate user must have read access to the users and groups in the global of your Active Directory. This is needed in order to expand SharePoint group members towards potential Active Directory groups and in turn to the actual Active Directory users.
Site Autodiscovery
Please note there is no native SharePoint API which provides site collection URLs without detours. A command like
Get-SPSite -Limit All | Select Url
Can only be executed in a SharePoint management shell on the SharePoint servers.
This is why the connector’s auto-discovery relies on the following heuristics:
SharePoint Search: a search for all STS_Sites object
SharePoint Search: a search for objects and usage of the given refiner values for SiteName
Moreover, you can add site collection URLs manually. For instance, by periodically executing the above given Get-SPSite call.
Content Source Configuration
The content source configuration of the connector comprises the following mandatory configuration fields.
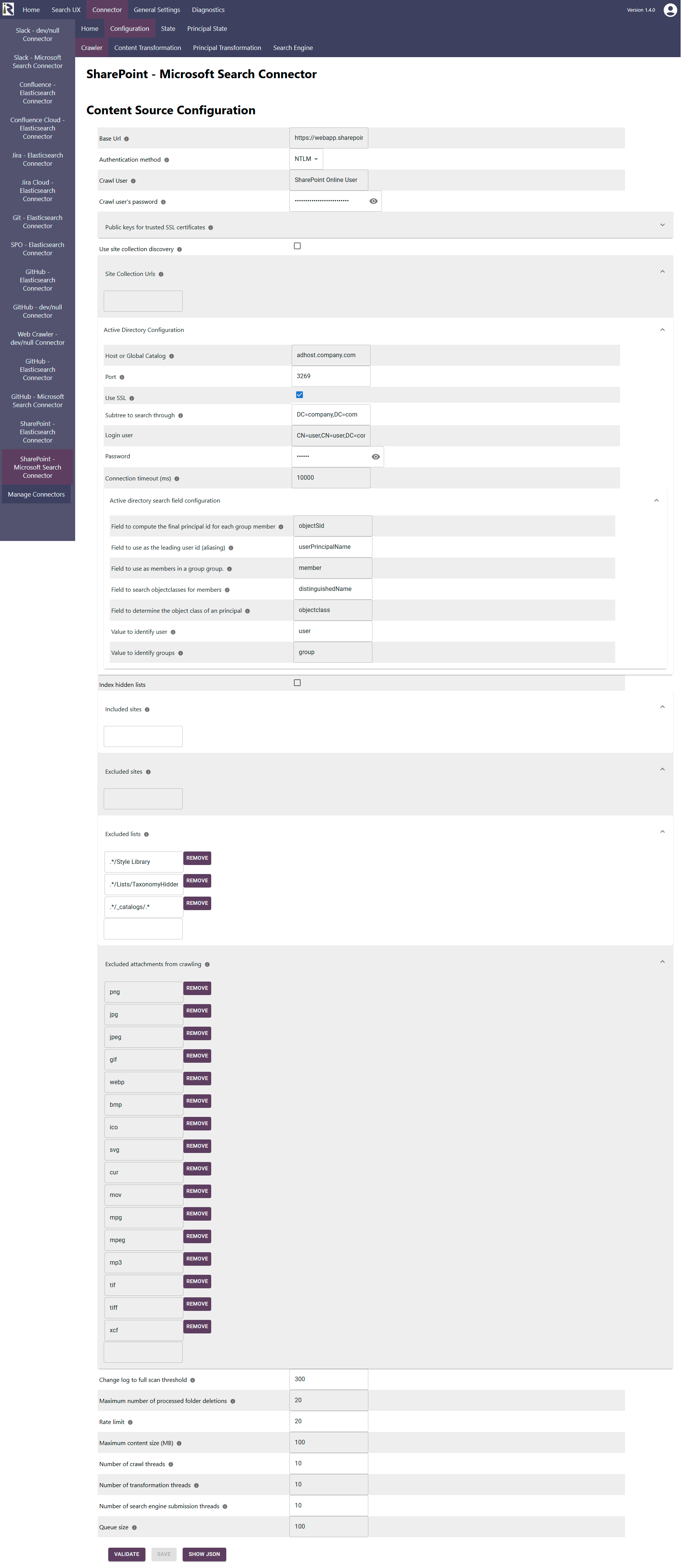
Within the connector’s configuration please add the following information:
Base Url. This is the base URL of your SharePoint installation. It is needed, if you want to enable site collection auto-discovery.
Authentication method. Here you need to choose NTLM or Kerberos.
Crawl user. This is the login name of the crawl user. The user must have the permissions as described above.
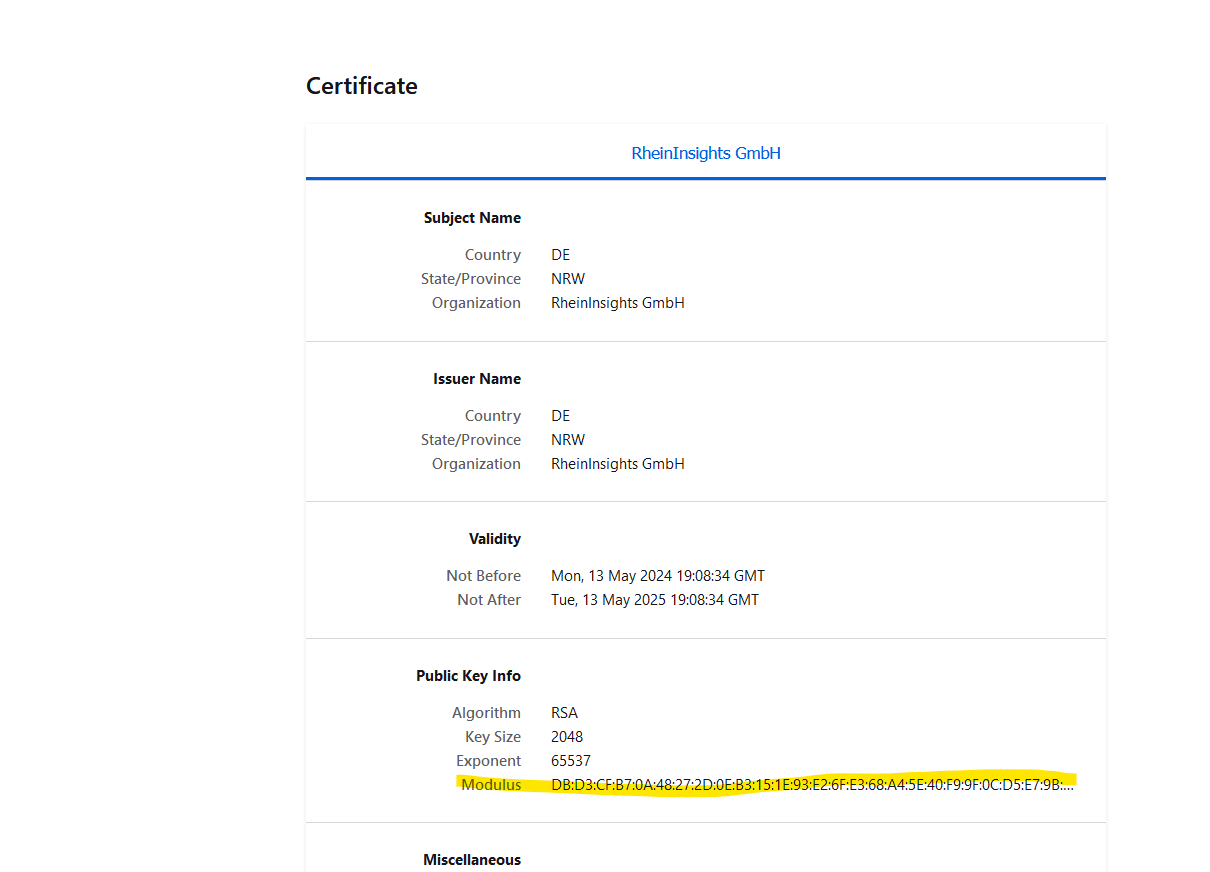
Public keys for SSL certificates: this configuration is needed, if you run the environment with self-signed certificates, or certificates which are not known to the Java key store.
We use a straight-forward approach to validate SSL certificates. In order to render a certificate valid, add the modulus of the public key into this text field. You can access this modulus by viewing the certificate within the browser.
Use site collection discovery. If turned on, the connector will use the SharePoint search index to identify all site collections. If turned off, you need to provide a list of site collection URLs in the field Site collection urls.
Active directory configuration
Host or global catalog. Please add the url of a domain controller, without protocol and port
Port here you can add the port to use for connecting against LDAP. LDAPS is 636, global catalog runs at 3269 with SSL.
Subtree to search through. This is the base tree to find Active Directory users and groups, below.
Login user. This is the CN of the user to connect against Active Directory
Password. This is the password for the user in 10.
Connection timeout. Determines how long the connector will wait until the connection is opened or a response comes back
Active Directory field configuration. The following fields are set by default for Active Directory and do not need to be changed.
Index hidden lists. This indicates that the connector should treat the no crawl flag and if turned off, the connector will not index anything which is flagged as no crawl.
Inclded Sites: here you can add site urls. If given, these only these sites will be crawled.
Excluded Sites: here you can add site urls. If given, these sites will be not be crawled.
Then all previously indexed sites which are not included anymore will be deleted from the search index.Excluded Lists: here you can add list urls. If given, these sites will be not be crawled.
Then all previously indexed listswhich are not included anymore will be deleted from the search index.Excluded attachments: the file suffixes in this list will be used to determine if certain documents should not be indexed, such as images or executables.
Change log to full scan threshold. Determines when the change processing should switch to scanning the site lists. If this amount of changes is reached for an incremental crawl, the connector will likely be faster with a full scan and thus it will not fetch the individual items but scans all items in batches.
Maximum number of processed folder deletions. This determines how many folder deletions in a change log run should be handled. As each deletion yields a recursive lookup against the connector database if items below are affected.
Rate limit. This determines how many HTTP requests per second will be issued against SharePoint.
After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source. If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Recommended Crawl Schedules
Content Crawls
The connector supports incremental crawls. These are based on the SharePoint changelog and depending on your tenant’s size, these can run every few hours or every 15 minutes.
The change log is complete and the connector handles deletions, individual role changes and more. However, it does not detect breaking up permission inheritance for lists. Also there are edge cases, where the change log might not be complete. Therefore depending on your requirements, we recommend to run a Full Scan every week.
For more information see Crawl Scheduling .
Principal Crawls
Depending on your requirements, we recommend to run a Full Principal Scan every day or less often.
For more information see Crawl Scheduling .