Documentation
Atlassian Confluence Connector
For a general introduction to the connector, please refer to RheinInsights Atlassian Confluence Server and Data Center Connector.
Confluence Configuration
Crawl User
The connector needs a crawl user which has the following permissions:
Read access to all spaces and pages, which should be indexed
Permission to access all space and page permissions
Read access to all users, groups
Read access to all group memberships
This means that for up to Confluence 8, you need to provide a user who is Space administrator for all spaces in crawl scope. Beginning with Confluence 9, you need to provide a Confluence administrator (token) to achieve Requirement 4 above.
Password Policy
The crawl user must have no password rotation or the password needs to be reset when it changes.
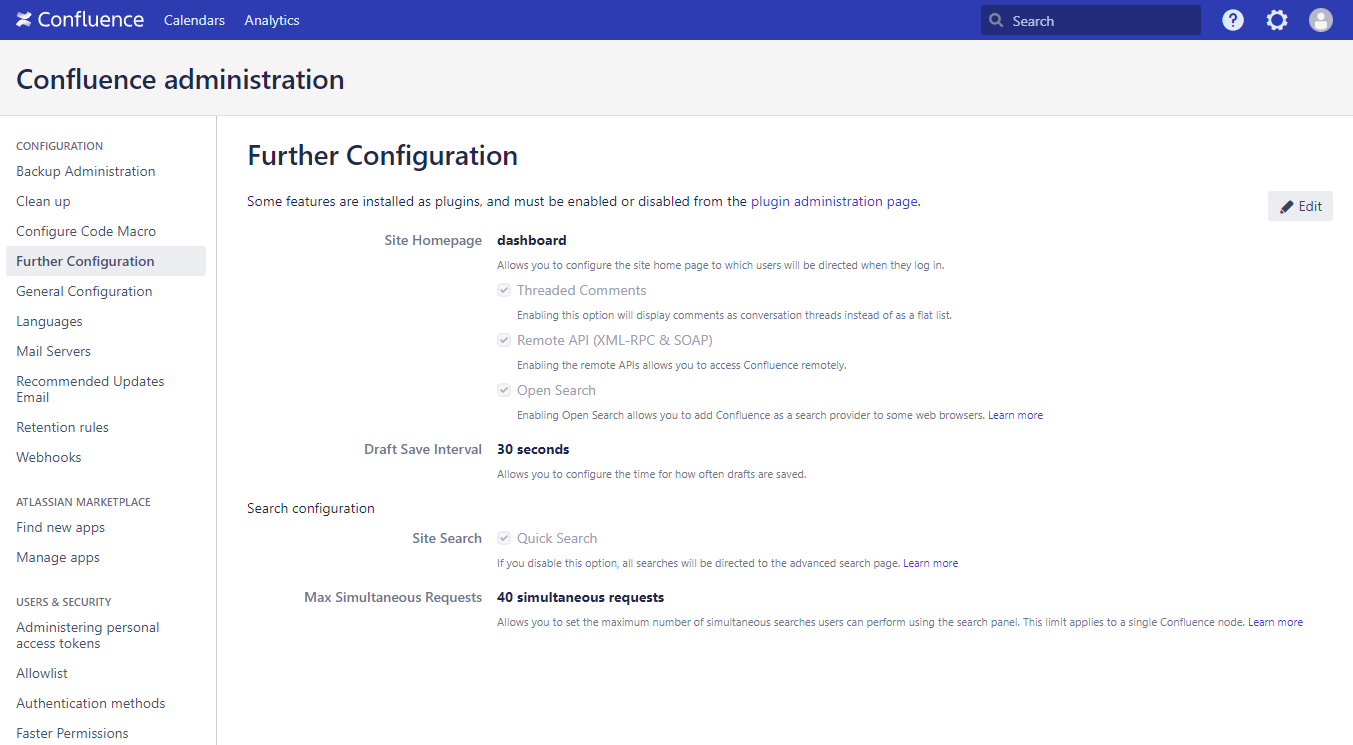
Legacy Remote APIs
The connector needs to access space permissions and unfortunately, there are no REST APIs available for these. Therefore, if you want to run the connector in an enterprise search scenario, please enable Remote API (XML-RPC & SOAP) at “Further Configuration” within the Confluence administration:
Content Source Configuration
The content source configuration of the connector comprises the following mandatory configuration fields.
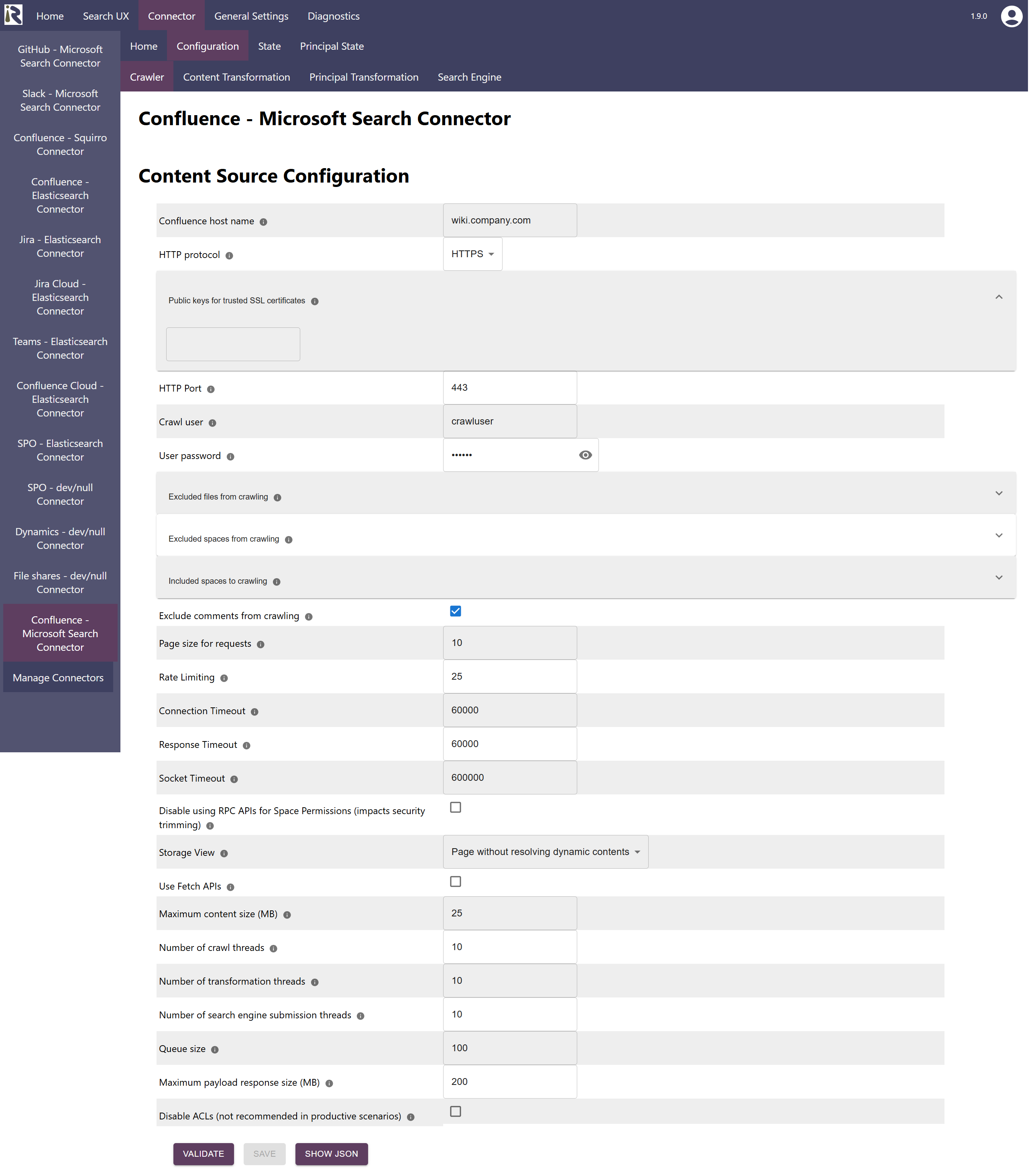
Confluence host name, which is the fully qualified domain name or host name of the Confluence instance, including port
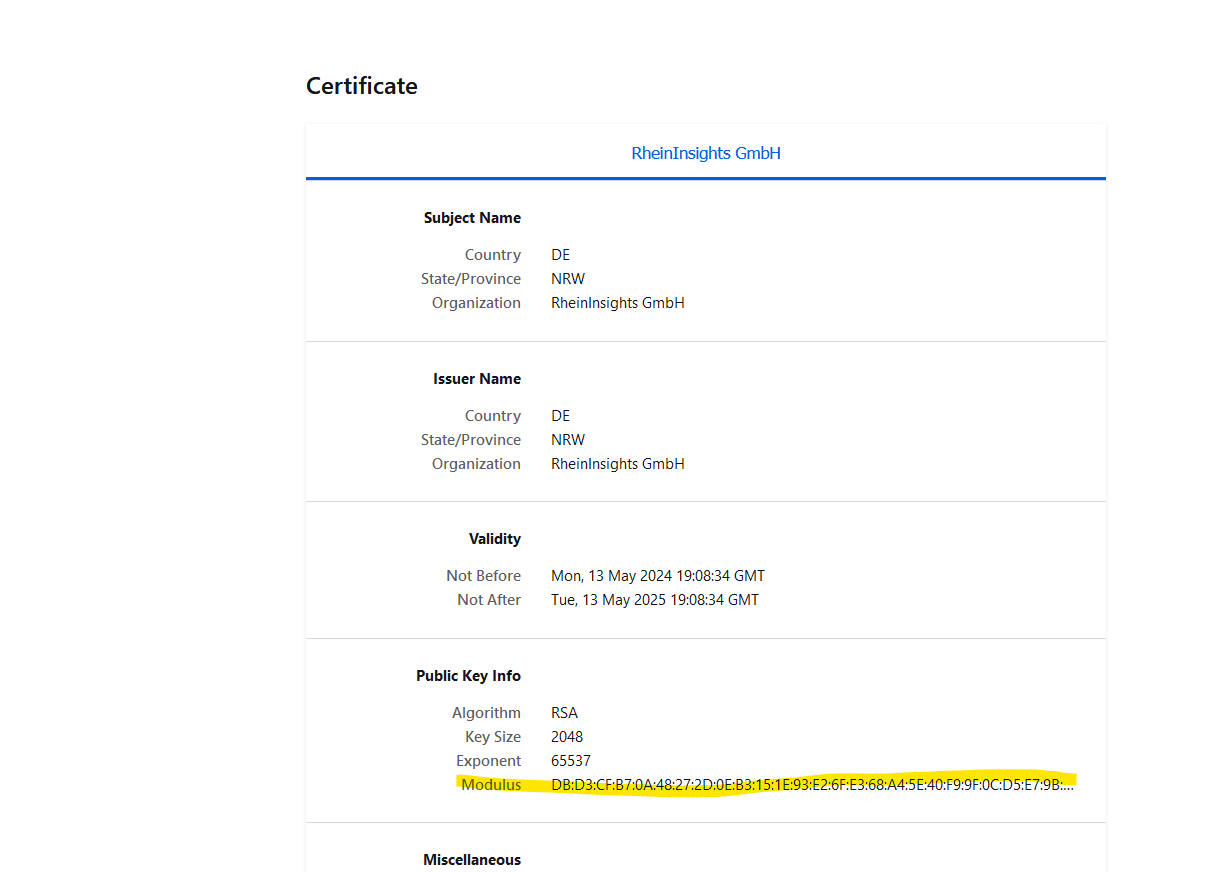
Public keys for SSL certificates: this configuration is needed, if you run the environment with self-signed certificates, or certificates which are not known to the Java key store.
We use a straight-forward approach to validate SSL certificates. In order to render a certificate valid, add the modulus of the public key into this text field. You can access this modulus by viewing the certificate within the browser.
Crawl user: is the user name which is used by the connector to crawl the instance. Please see the section above for the necessary user permissions.
User password: is the corresponding password for the crawl user
Excluded files from crawling: here you can add file extensions to filter attachments which should not be sent to the search engine.
Excluded spaces from crawling: here you can add space names or keys to exclude these from crawling
Please note that a change to this list will yield an incremental crawl to remove all pages and attachments from excluded spaces.Included spaces from crawling: this is an include list. If empty, all spaces but the excluded spaces are indexed. But if you add at least one entry (even an empty one), only this space will be included for crawling. Please note that a change to this list will yield an incremental crawl to remove all pages and attachments from excluded spaces.
Enable page postprocessing. If enabled (recommended), the connector performs lookups for people references on Confluence pages. Moreover, it extracts the titles for page references on a Confluence page.
Exclude comments from crawling. If not checked, the document bodies will contain the Confluence comments. For performance reasons, you can disable this feature.
Perform separate call to fetch attachments. If enabled, a separate call is performed per page to extract the attachments on the page. If disabled, a REST expansion is used to fetch this information.
Compute new attachment ids (recommended). If enabled, attachment ids are prefixed with “att”.
Page size for requests. Defines how many pages will be fetched per API request. Default is 100.
Rate Limiting. This will define a rate limiting for the connector, i.e., limit the number of API requests per second (across all threads).
Response timeout (ms). Defines how long the connector until an API call is aborted and the operation be marked as failed.
Connection timeout (ms). Defines how long the connector waits for a connection for an API call.
Socket timeout (ms). Defines how long the connector waits for receiving all data from an API call.
Disable using RPC APIs for Space Permissions (impacts security trimming). Will disable lookups against the Confluence RPC APIs but also disable permissions.
Storage View. This defines if fully rendered pages (i.e., Confluence macros being expanded) will be used or not.
Use fetch APIs. Defines if scan pages should be used or the fetch pages API. Scan pages API is more efficient and does scale well even for a space with thousands of pages.
Enable fetching rendered content. If enabled, you need to provide one or multiple strings in the field matching strings. If one of these strings is discovered in a page, then the connector will fetch the rendered contents of the page.
This is for instance helpful for pages which contain complex and dynamic macros which otherwise would not be visible to the connector.
Please note that the connector will only fetch the page again, if the page itself changed. This is independent from the dynamic data which might be shown in a macro. I.e., if the macro data changes because other pages have changed, then the connector will not be able to detect this for efficiency reasons.The general settings are described at General Crawl Settings and you can leave these with its default values.
After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source. If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Limitations for Incremental Crawls and Recommended Crawl Schedules
Atlassian Confluence does not offer a complete change log. This means that incremental crawls can detect new and changed Confluence spaces, pages and attachments. However, removed spaces, pages and attachments will not be detected in incremental crawls, as well as significant changes to the space permission schemes.
Therefore, we recommend to configure incremental crawls to run every 15-30 minutes, full scan principal crawls to run twice a day, as well as a weekly full scan of the documents of the Confluence instance. For more information see Crawl Scheduling .