Documentation
OData via REST Connector
For a general introduction to the connector, please refer to https://www.rheininsights.com/en/connectors/odata.php .
OData / Rest Configuration
Crawl User
The connector can use a crawl user to authenticate against the provided API in two ways. Either it uses basic authentication or can work with application permissions as an Entra Id application.
API Design and Expected Return Values
Content APIs
The connector queries a given base Url. This API must return a response such as
{
“value”:[
{…}…
],
“@odata.nextLink”:”…” // is used for paging
}
Paging: For paging reasons, the response must return a @odata.nextLink.
Values must be given in a field called value. Each object within value is interpreted as key-string-array paris. The following predefined fields are interpreted separately:
"id":"...", // a unique document key
"url":"...", // a url to display as search result URL
"allowAcl":[ // a list of allow-principals (user or group is defined by each type)
{
"id":"PrincipalId",
"isDeletePrincipal":false,
"type":"USER|GROUP"
},...
],
"denyAcl":[ // a list of deny-principals (user or group is defined by each type)
{
"id":"PrincipalId",
"isDeletePrincipal":false,
"type":"USER|GROUP"
},...
],
"title":"...", // the title to display with the search result
"rootItemUrl":"..." // the root item title to display with the search result
"rootItemTitle":"..." // the root item url to display with the search result
"parentItemTitle":"..." // the parent item title to display with the search result
"parentItemUrl":"..." // the parent item URL to display with the search result
Principal APIs
If a principal crawl is wanted, the connector queries a second Url. This API must return a response such as
{
“value”:[
{…}…
],
“@odata.nextLink”:”…” // is used for paging
}
Paging: For paging reasons, the response must return a @odata.nextLink.
Values must be given in a field called value. Each object must be a principal with nested members or parents, as follows
{
"id":"PrincipalId",
"isDeletePrincipal":false,
"type":"USER|GROUP",
"parentPrincipals":[
{
"id":"PrincipalId",
"isDeletePrincipal":false,
"type":"USER|GROUP",
}, ...],
"members":[
{
"id":"PrincipalId",
"isDeletePrincipal":false,
"type":"USER|GROUP",
}, ...]
}
Parent Principals are groups which this principal is member of.
Members determine members in this group.
Both directions are supported by the connector.
Content Source Configuration
The content source configuration of the connector comprises the following mandatory configuration fields.
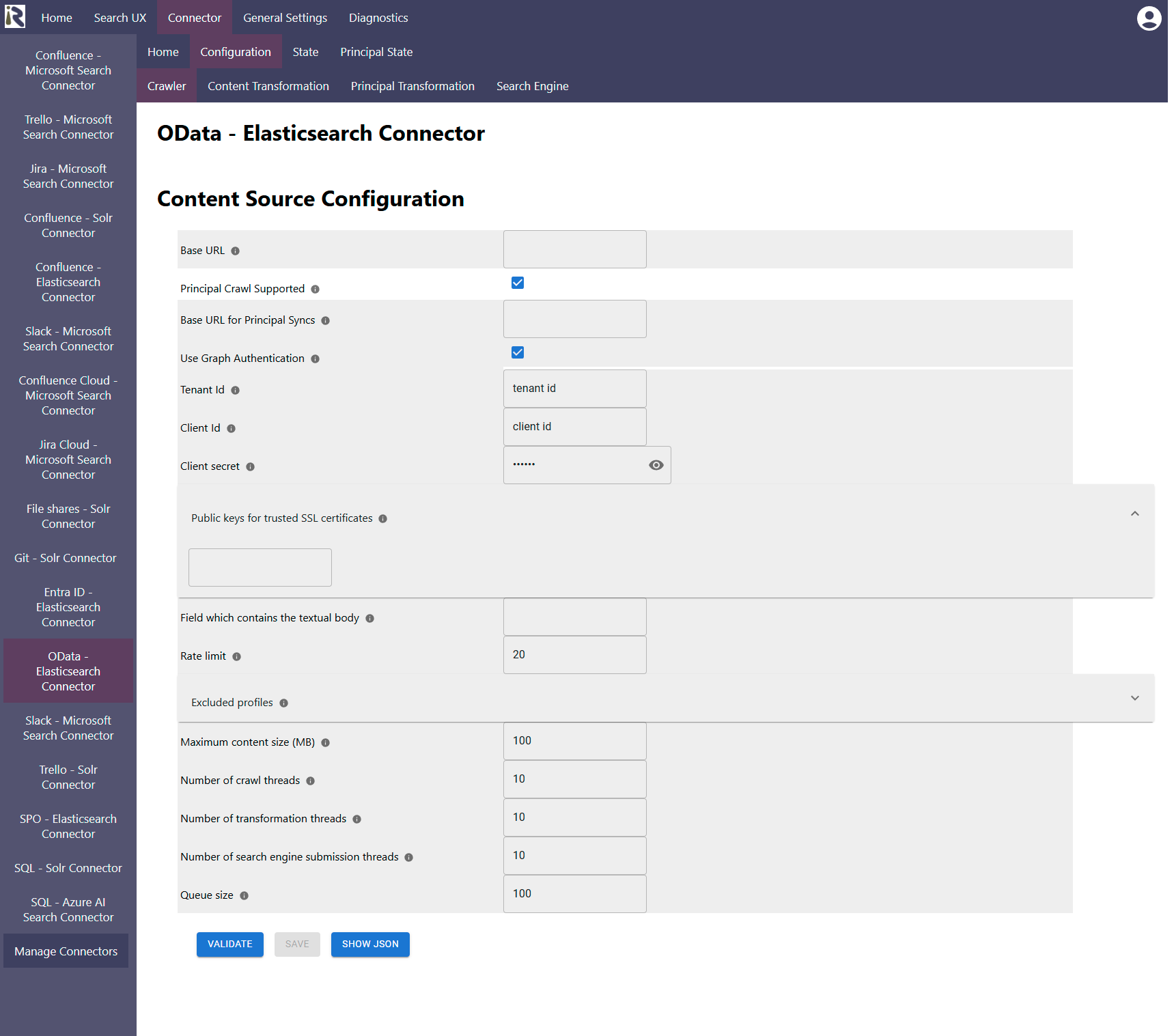
Base URL: is the API endpoint to start crawls against
Principal Crawl Supported: enable this in order to index user group relationships from a separate API.
Base URL for Principal Sync: is the URL which the connector uses to extract principals from.
Use Graph Authentication: keep it disabled to use basic authentication or no authentication at all.
Use Graph Authentication not checked:
Username: is the username for basic authentication
Password: is the according password
Use Graph Authentication checked:
Please register an according Entra Id enterprise application, e.g. following the steps at Microsoft Entra ID Connector .
Tenant Id: determines the tenant id where the application is registered
Client Id: is the according client id
Client secret: is the secret as generated in the app registration.
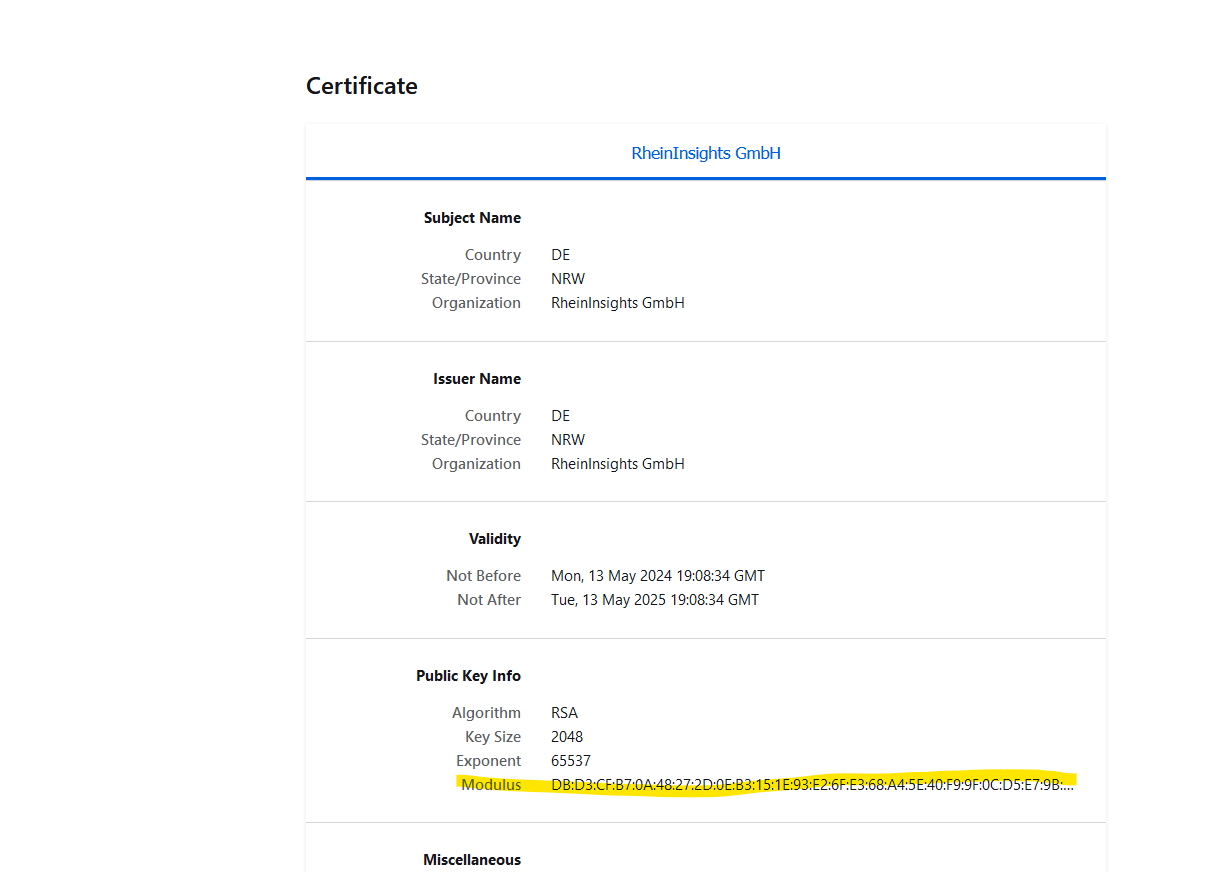
Public keys for SSL certificates: this configuration is needed, if you run the environment with self-signed certificates, or certificates which are not known to the Java key store.
We use a straight-forward approach to validate SSL certificates. In order to render a certificate valid, add the modulus of the public key into this text field. You can access this modulus by viewing the certificate within the browser.
Field which contains the textual body: is the field which should be used in the content transformation as the body field which is also sent separately to the search index.
After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source. If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Recommended Crawl Schedules
Depending on your source and requirements, we recommend to run a Full Scan every half day or even more often.
Principal crawls should run once a day. For more information see Crawl Scheduling .