Documentation
Atlassian Confluence Cloud Connector
For a general introduction to the connector, please refer to https://www.rheininsights.com/en/connectors/confluence-cloud.php .
Confluence Cloud Configuration
Crawl User
The connector uses a crawl user which has the following permissions:
Read access to all spaces and pages, which should be indexed
Permission to access all space and page permissions
Read access to all users and groups (i.e., must be space administrator)
API Key
The connector uses a username and an API key to authenticate against Confluence Cloud. You can create the API key following the steps at Manage API tokens for your Atlassian account | Atlassian Support.
Admin API Key
The Atlassian APIs do not expose mail-addresses for users straight-forwardly. Therefore, the principal synchronization needs to access the admin APIs of your tenant. The method called is
https://api.atlassian.com/admin/v1/orgs/<YOUR TENANT ID>/users/search
In order to authorize the connector to call this API, you need to get an according, second API token. Please follow the steps as described here Manage an organization with the admin APIs | Atlassian Support and create an API key without scopes. Also please write down your organization Id, as it is needed below.
API key without scopes is needed, as there is no fine-granular permission as of now which allows for accessing the uses search.
Content Source Configuration
The content source configuration of the connector comprises the following mandatory configuration fields.
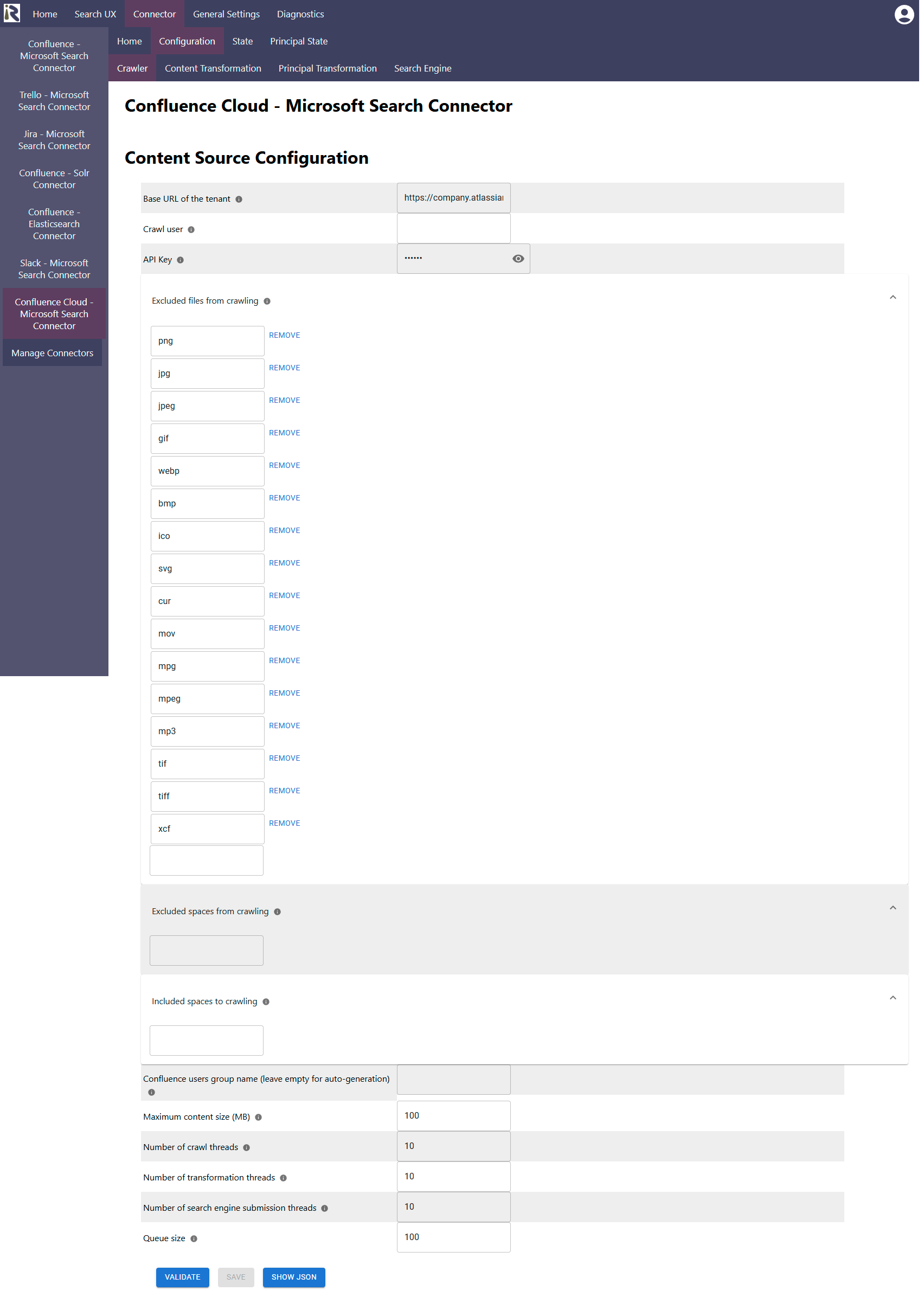
Base URL of the tenant: is the url of your Atlassian tenant, e.g., https://company.atlassian.net
Crawl user: is the user name which is used by the connector to crawl the instance. Please see the section above for the necessary user permissions.
API Key: is used for the user authentication. It is created as described here https://www.rheininsights.com/en/connectors/confluence-cloud.php.
Admin API Key: is used for the API to access the admin API. It is created as described here .
Organization Id. This is the organization id as can be found in your admin URL, by opening
https://admin.atlassian.com/and then taking a note of the following URLs:https://admin.atlassian.com/o/<YOUR_ORG_ID>/admin-apior during the Admin API Key registration.Excluded files from crawling: here you can add file extensions to filter attachments which should not be sent to the search engine.
Excluded spaces from crawling: here you can add space names or keys to exclude these from crawling
Please note that a change to this list will yield an incremental crawl to remove all pages and attachments from excluded spaces.Included spaces from crawling: this is an include list. If empty, all spaces but the excluded spaces are indexed. But if you add at least one entry (even an empty one), only this space will be included for crawling. Please note that a change to this list will yield an incremental crawl to remove all pages and attachments from excluded spaces.
Enable page postprocessing. If enabled (recommended), the connector performs lookups for people references on Confluence pages. Moreover, it extracts the titles for page references on a Confluence page.
Confluence users group name: here you can add the name of the confluence-users group (i.e., everyone for this tenant). If you leave it empty, the connector will extract your tenant name from the Base URL given in (1) to compute confluence-users-company.
The general settings are described at General Crawl Settings and you can leave these with its default values.
Validate: After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source.
Save: If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Limitations for Incremental Crawls and Recommended Crawl Schedules
Atlassian Confluence does not offer a complete change log. This means that incremental crawls can detect new and changed Confluence spaces, pages and attachments. However, removed spaces, pages and attachments will not be detected in incremental crawls, as well as significant changes to the space permission schemes.
Therefore, we recommend to configure incremental crawls to run every 15-30 minutes, full scan principal crawls to run twice a day, as well as a weekly full scan of the documents of the Confluence instance. For more information see Crawl Scheduling .