Documentation
Drupal CMS Connector
For a general introduction to the connector, please refer to RheinInsights Drupal CMS Enterprise Search und RAG Connector.
Drupal Configuration
Our connector uses the module JSON-API for crawling. This means you need to enable the following modules in your Drupal instance.
Therefore, as an administrator do the following
Open your Drupal instance
Open the administration bar
Click on Extend
Enable the module JSON:API
Enable the module Serialization
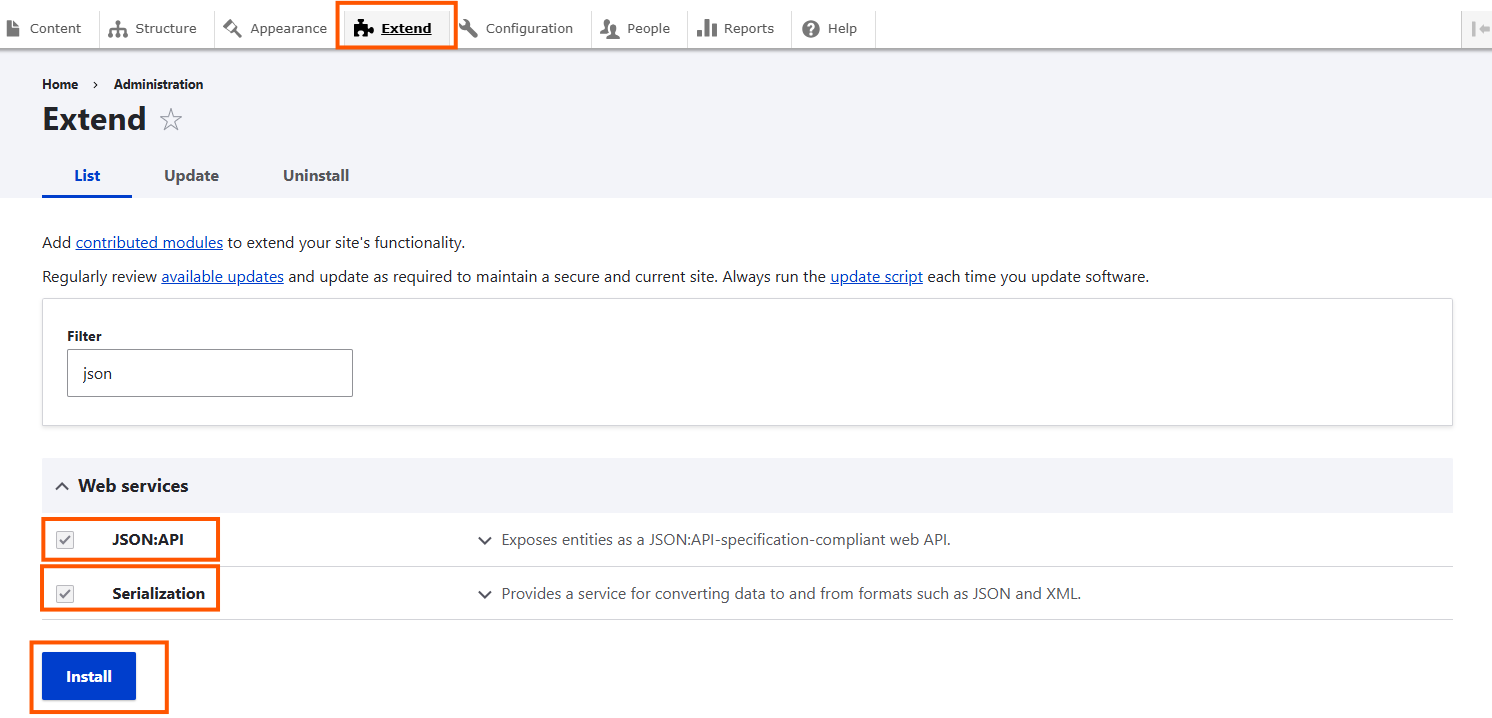
Enable the module HTTP Basic Authentication
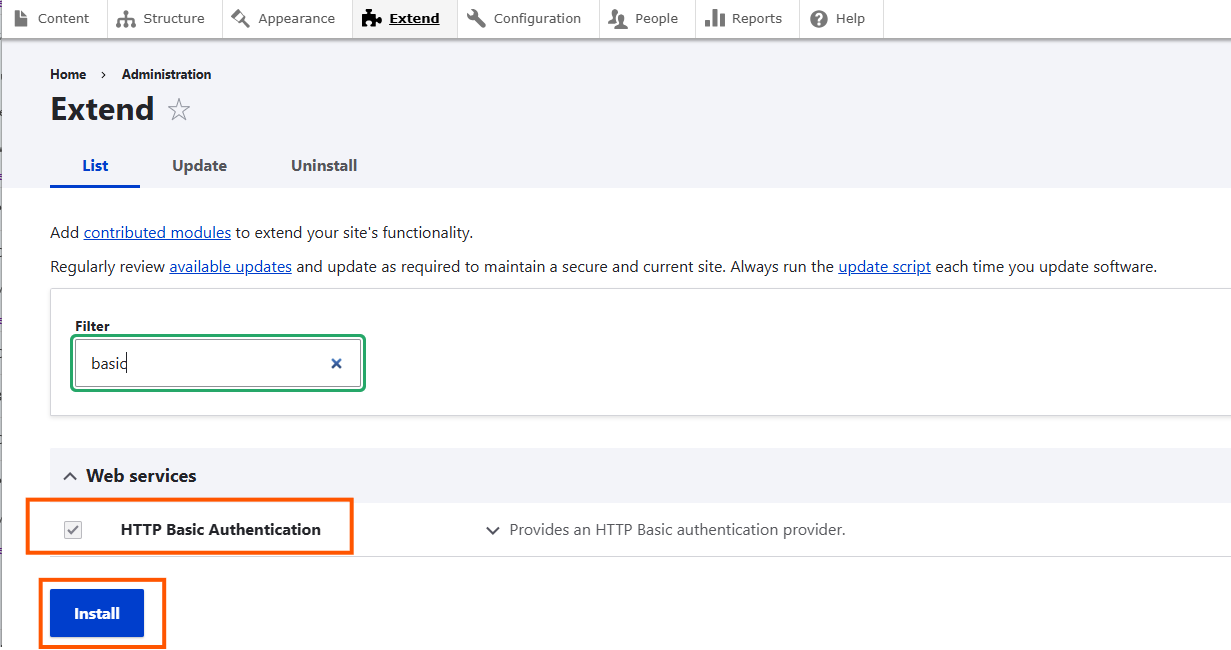
Click on install
Go to Configuration > Web Services > Json:API
Limit allowed operations to Accept only JSON:API read operations
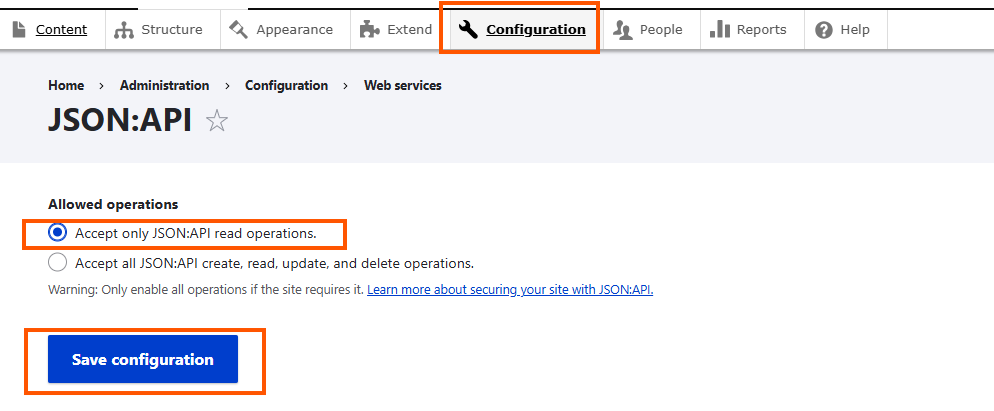
Save the configuration
Crawl User
The connector needs a crawl user which has the following permissions:
Read access to all pages (nodes), which should be indexed
Read access to all media, which should be indexed
Read access to the entity definitions and languages
The connector uses Basic Auth to authenticate against Drupal.
Content Source Configuration
The content source configuration of the connector comprises the following mandatory configuration fields.
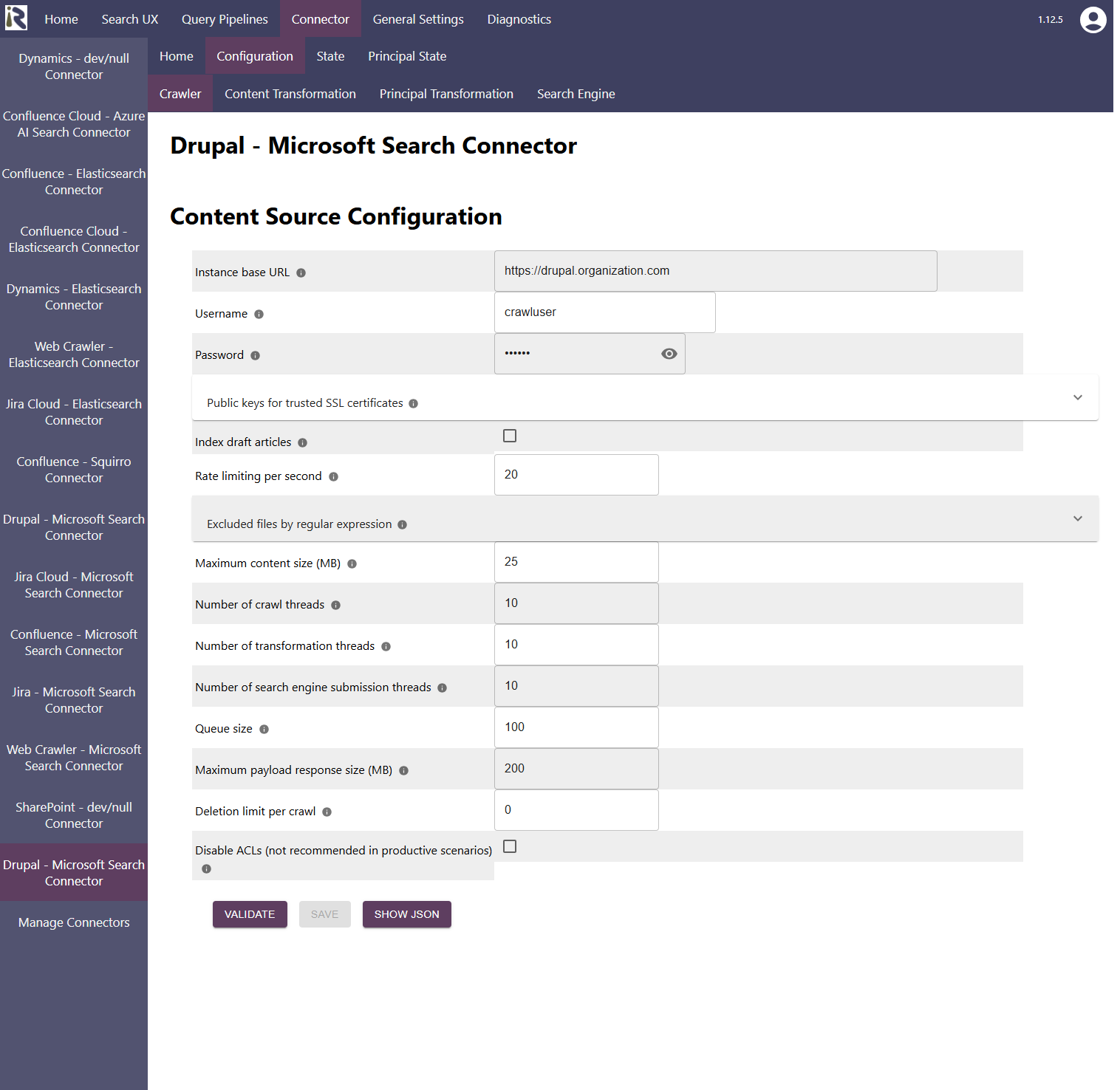
Instance base URL, which is the fully qualified domain name or host name to the Drupal instance
Username: is the username of the crawl user
Password: is the password for this crawl user
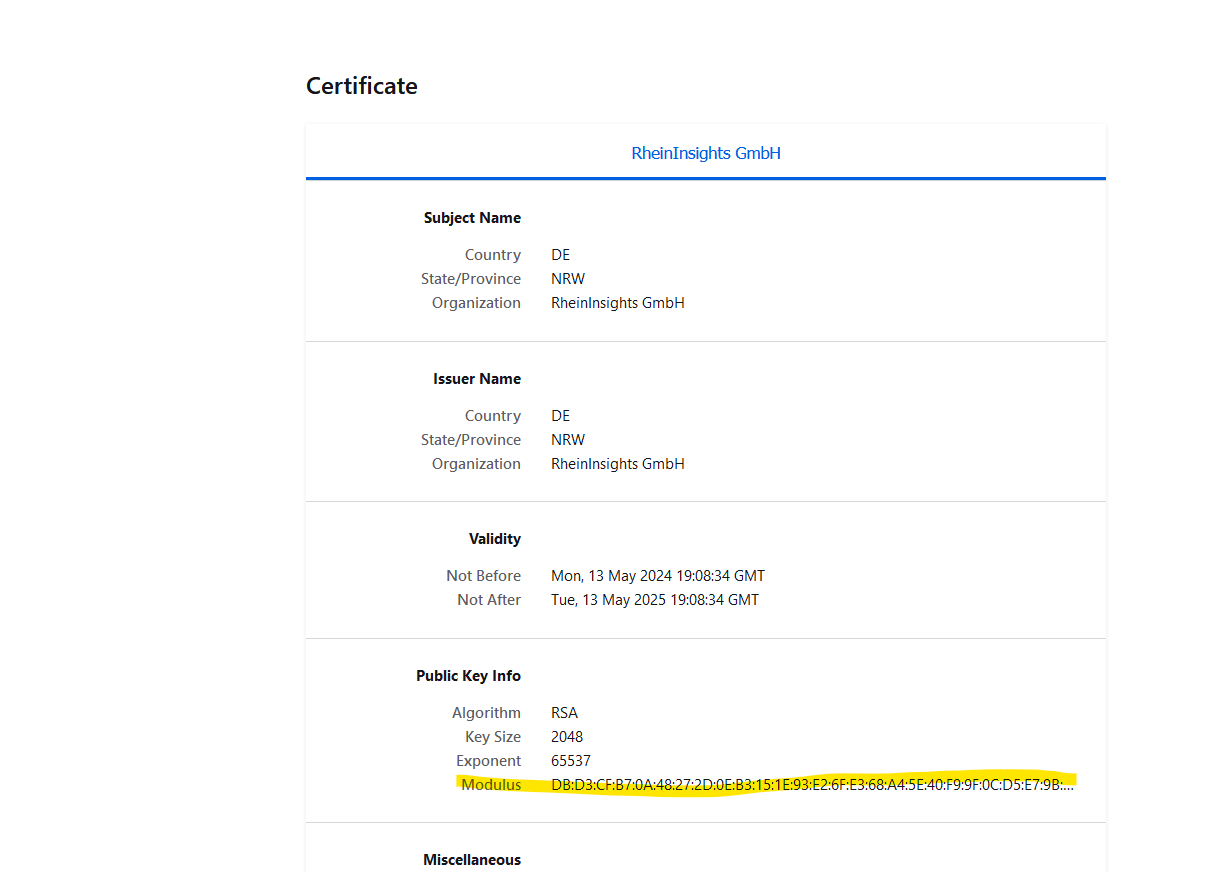
Public keys for SSL certificates: this configuration is needed, if you run the environment with self-signed certificates, or certificates which are not known to the Java key store.
We use a straight-forward approach to validate SSL certificates. In order to render a certificate valid, add the modulus of the public key into this text field. You can access this modulus by viewing the certificate within the browser.
Index draft articles: if enabled then also draft articles are indexed. Otherwise only articles in published state.
Excluded files from crawling: here you can add file extensions to filter attachments which should not be sent to the search engine.
Rate Limiting. This will define a rate limiting for the connector, i.e., limit the number of API requests per second (across all threads).
Response timeout (ms). Defines how long the connector until an API call is aborted and the operation be marked as failed.
Connection timeout (ms). Defines how long the connector waits for a connection for an API call.
Socket timeout (ms). Defines how long the connector waits for receiving all data from an API call.
The general settings are described at General Crawl Settings and you can leave these with its default values.
After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source. If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Limitations for Incremental Crawls and Recommended Crawl Schedules
Drupal does not offer a change log. This means that incremental crawls can detect new and changed Drupal articles and media items. However, deleted articles or media items will not be detected in incremental crawls.
Therefore, we recommend to configure incremental crawls to run every 15-30 minutes, as well as a weekly full scan of the documents of the Drupal instance. For more information see Crawl Scheduling .