Documentation
Google Drive Connector
For a general introduction to our Google Drive Connector, please refer to https://www.rheininsights.com/en/connectors/google-drive.php .
Google Drive Configuration
Our Google Drive Connector is intended to index all documents from an organization. This means that it needs the following
Service Account User
This service account authenticates using a JSON secret and thus the policy disableServiceAccountKeyCreation must be disabled
The service account must use domain-wide delegation
You need to enable Google Drive APIs and Google Admin Directory APIs for this service account
In order to set up the crawl user, please proceed as follows:
Create a new Project
Open https://console.cloud.google.com/cloud-resource-manager
Create a new project, name it such as “Google Drive Connector”
Enable the APIs
Open the project
Open API & Services

Click on Enable APIs und Services
Search for Google Drive API and click on it
Hit enable API
Go back to Enable APIs und Services
Search for Admin SDK API and click on Admin SDK API
Click on enable
Create a Service Account
Within the project search, open the service accounts dialog in IAM
Click on Create Service Account
Give it a name and click on create and continue
At Grant this service account access to project, click Done
At Grant users access to this service account, click Done
In the next dialog, click on the newly created service account
Click on Keys
Click on Add Key
Click on Create new key
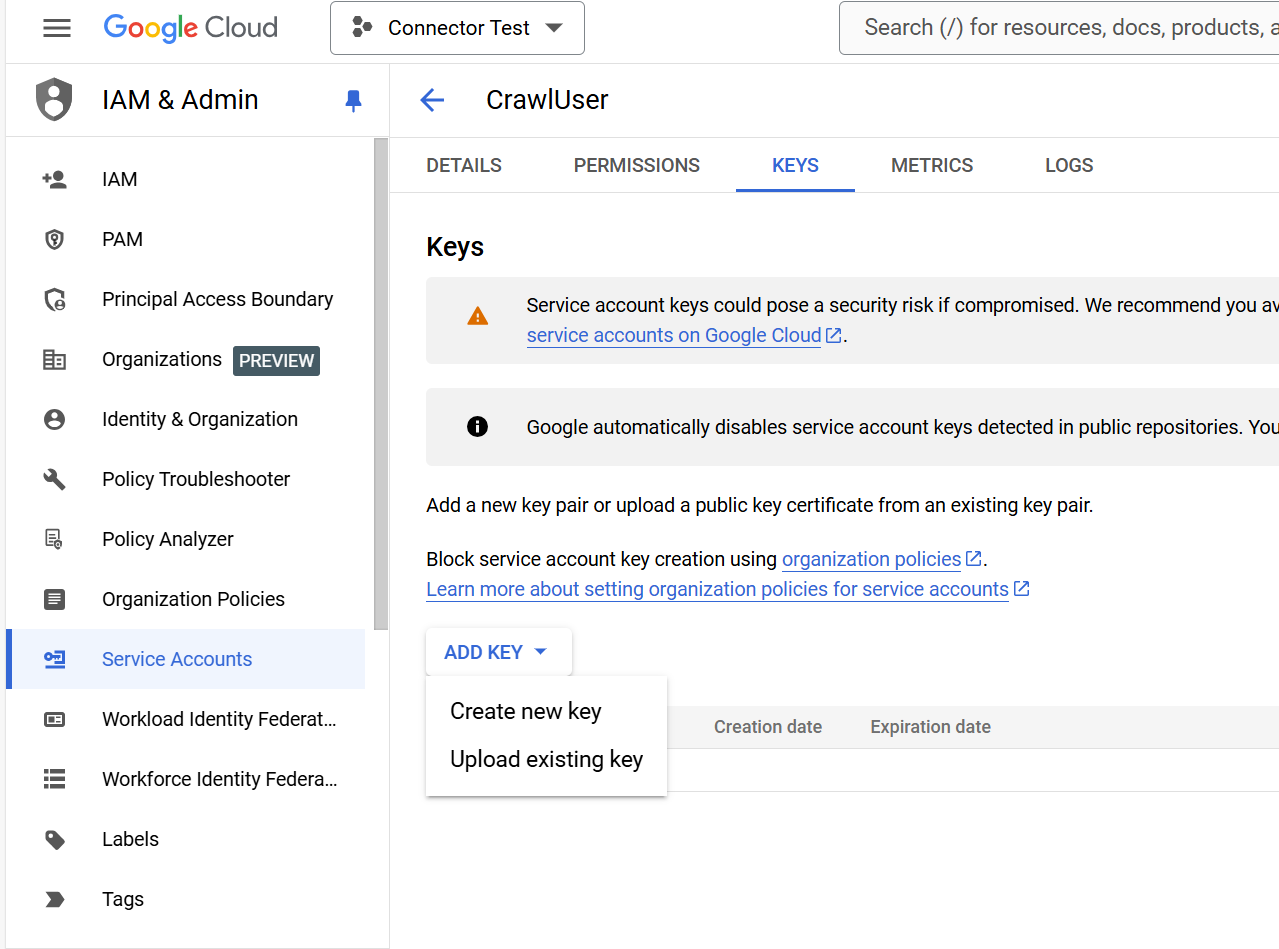
Choose JSON

Enable Domain-Wide Delegation
Copy the service account’s Unique ID from the service account’s detail view
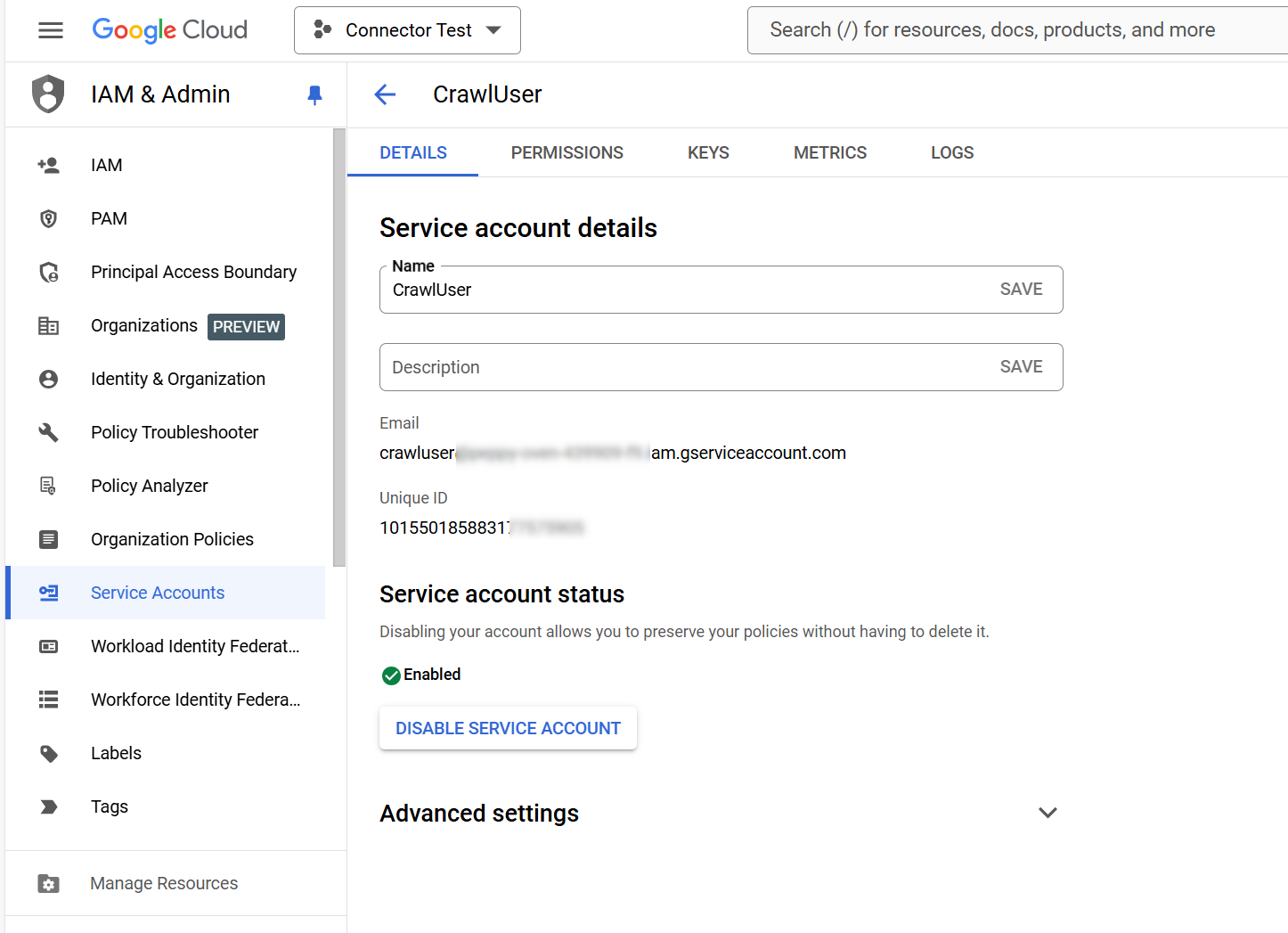
Go to Domain-wide Delegation in the Google Workspace Admin Console
Click on Add New
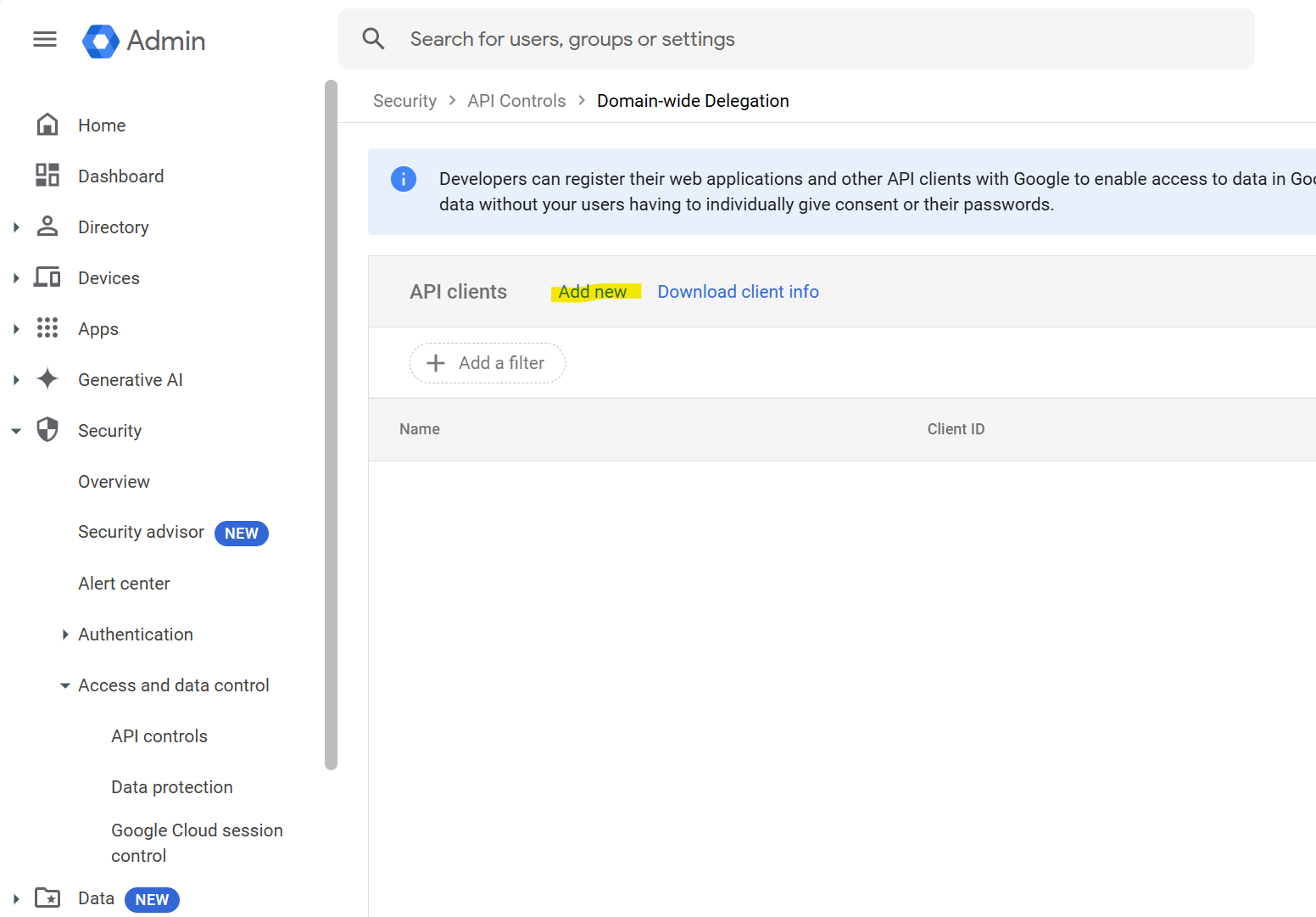
Enter the unique id of the crawl account
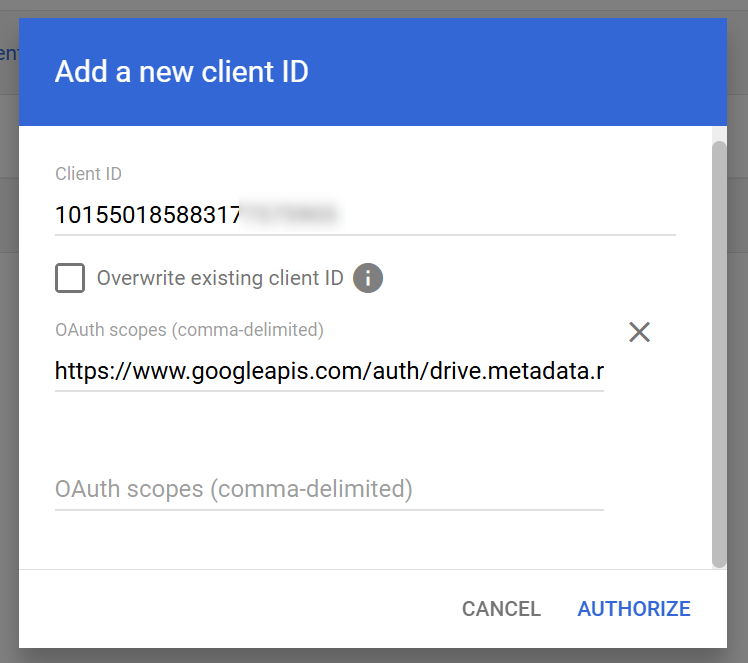
and the following scopes
https://www.googleapis.com/auth/drive.metadata.readonly,
https://www.googleapis.com/auth/drive.file,
https://www.googleapis.com/auth/drive.readonly,
https://www.googleapis.com/auth/admin.directory.group,
https://www.googleapis.com/auth/admin.directory.user,
https://www.googleapis.com/auth/admin.directory.group.member.readonly
Customer Id
Go to https://admin.google.com > Account > Account Settings > Profile and make a note of your customer Id
Content Source Configuration
The content source configuration of the connector comprises the following mandatory configuration fields.
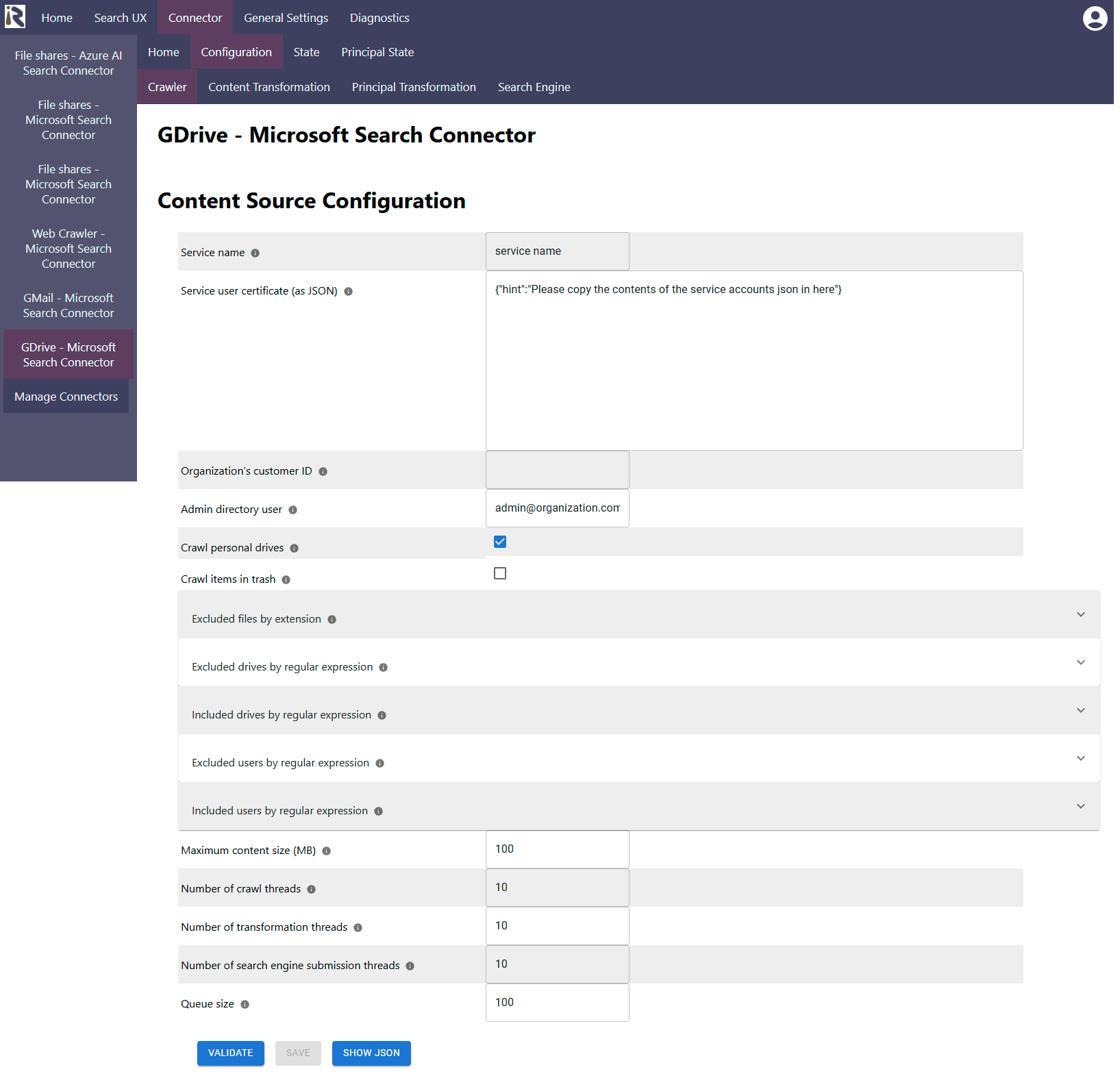
Service name: This identifier is used to tell the Google APIs who is connecting against them. You will find this id in the API metrics in your Google Cloud project.
Service user certificate (as JSON): Here you need to paste the contents of the private key for the crawl user into. You generated this in one of the steps above.
Organization's customer ID: Here you need to add your organization Id into. Above, we described, where you can find this ID.
Admin directory user: Here you have to add a valid e-mail address of an Google Directory admin into. This admin needs to have view permission of users, groups and user-group relationships in your Admin Directory.
Crawl personal drives: This flag tells the connector to crawl or skip personal drives. By default, we recommend indexing also personal drives.
Crawl items in trash: Enable this flag, if you like to still index items which are in the Google Drive trashes. By default, this flag is disabled.
Excluded files by extension: here you can add a list of file suffixes which will be filtered out while crawling and not being indexed at all.
Excluded drivesby regular expression: here you can add regexes or individual shared drive ids or names to exclude the drives for these users from crawling.
Included drives by regular expression: here you can add regexes or individual shared drive ids to only include these drive(s) in crawling.
Excluded users by regular expression: here you can add regexes or individual user Ids to exclude the drives for these users from crawling. Please note that all users who have access to a specific shared drive are excluded, the connector will not index this shared drive, too.
Included users by regular expression: here you can add regexes or individual user Ids to only include their drive(s) in crawling.
Include delegates in ACL: Enable this flag to include delegate users in the ACLs. Each mailbox comes with a Group ACL and delegate users will be part of this group. Otherwise, it will be just the owner.
Maximum content size (MB): This is file size limitation. If files exceed this size, they won’t be crawled.
The general settings are described at General Crawl Settings and you can leave these with its default values.
Permissions to an item in a personal Drive are limited to the owners, as well as users where the file has been explicitly shared with. If a document is shared to everyone who has a link, then the connector ignores this permission. |
|---|
After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source. If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Recommended Crawl Schedules
Google Drive offers a complete change log. So the connector can efficiently detect new, updated and deleted mails and attachments. However, due to the vast amount of changes in an organization, it may vary how quickly the connector is able to get through all changes.
However, we recommend to configure incremental crawls to run every 60 minutes.
Principal scans should run twice per day. These pick up the user group relationships, which are important for shared drives.
Furthermore, full content scans are normally not needed for Google Drive, only if you change content processing and need to reindex everything. For more information see Crawl Scheduling .