Documentation
Slack Connector
For a general introduction to our Slack Connector, please refer to RheinInsights Slack Enterprise Search and RAG Connector.
Slack Configuration
Crawl User
The connector uses a
bot token or
user token
to authenticate against Slack.
If you configure a bot token for the connector, the bot needs to be added to all channels, which you like to crawl. This gives you a broader flexibility when it comes to private channels. However, it will not by default all public channels. A user token in contrast will allow to crawl all channels the owning user sees to be crawled, optionally including archived channels.
In order to acquire such a user token, please follow the steps below:
Click on “Create a new app”
Choose from Scratch
Add an app name and choose your workspace, which you would like to crawl
Open OAuth & Permissions
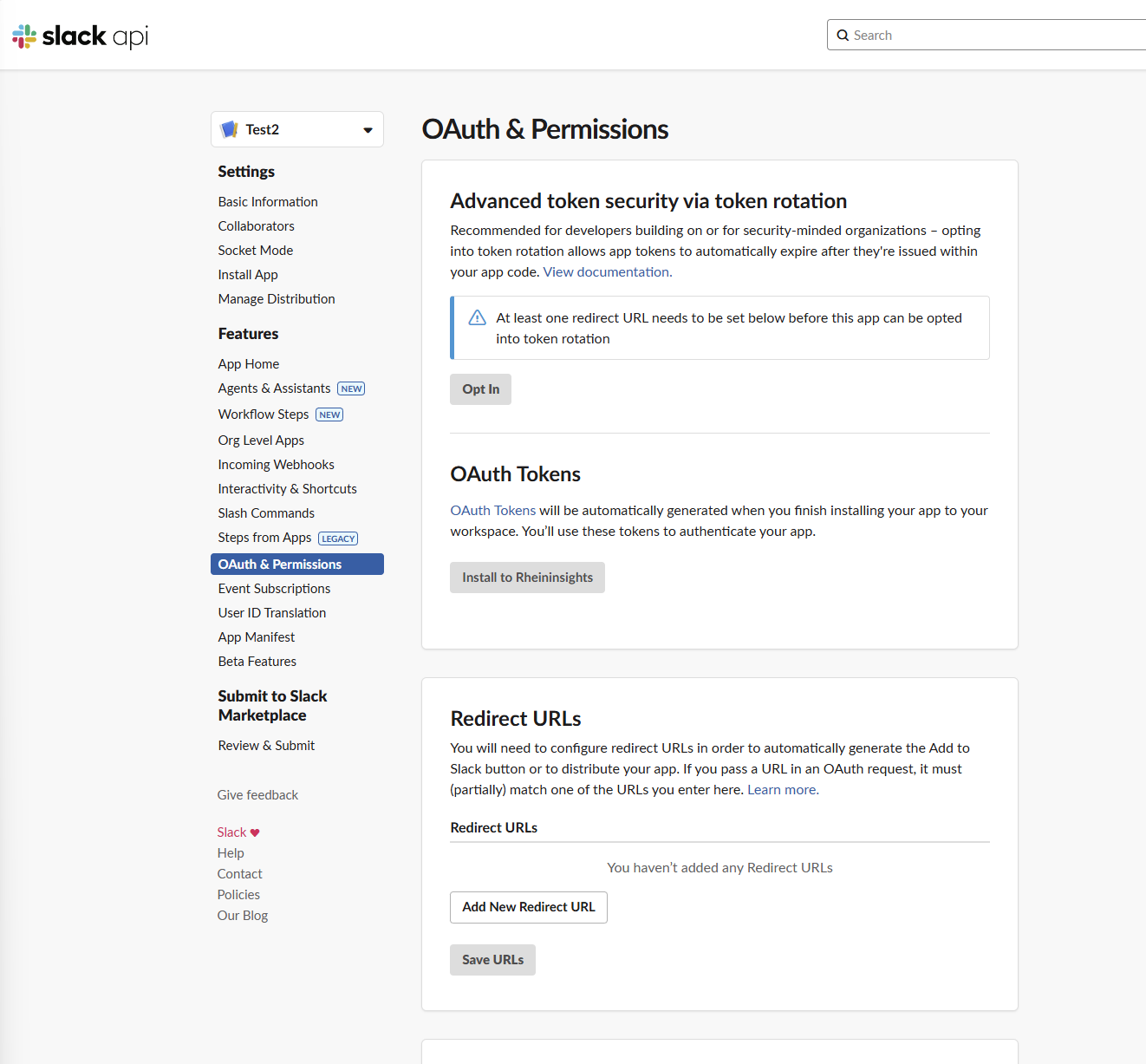
On this page browse to scopes and either for Bot Token Scopes or User Token Scopes click on Add an Oauth Scope
Assign the following permissions:
channels:history
channels:read
files:read
remote_files:read
team:read
users:read
users:read.email
groups:read
groups:history
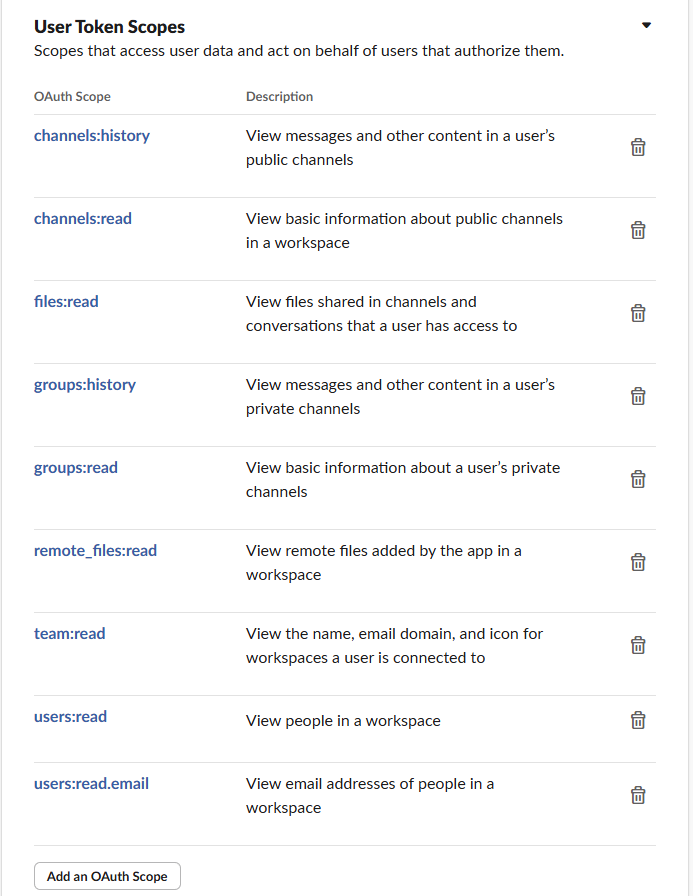
Scroll up and click on Install to <Tenant Id>
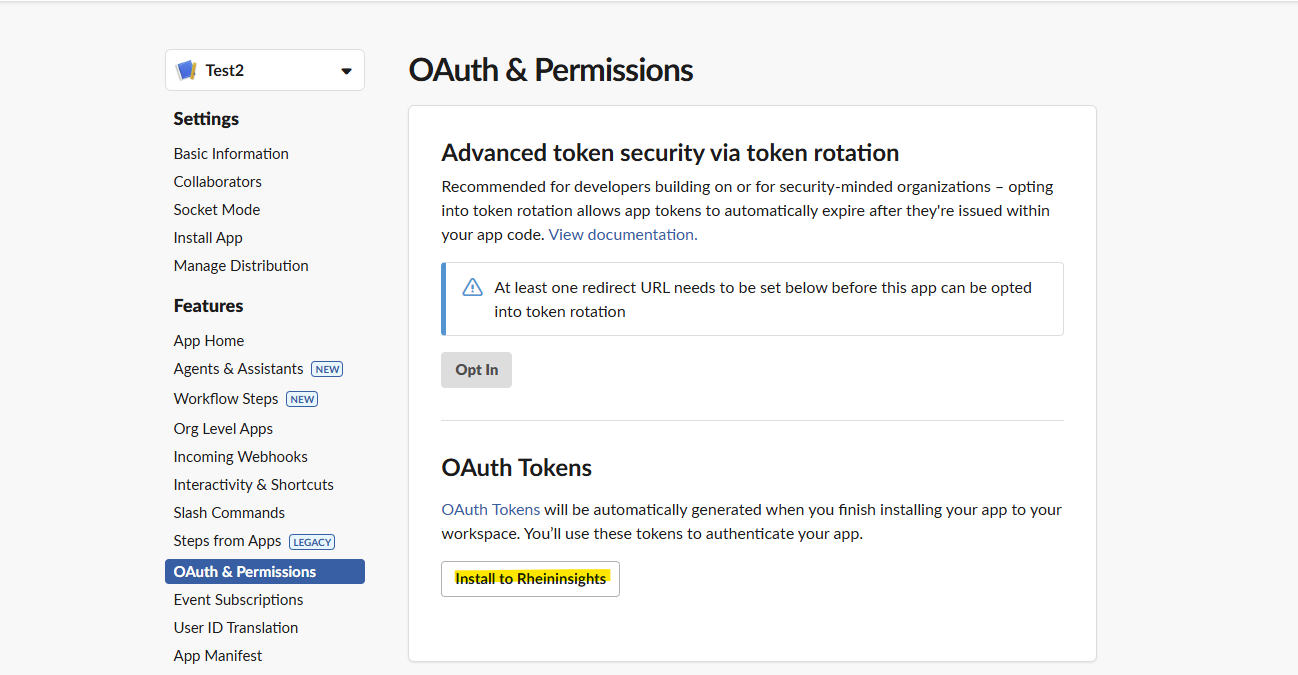
Take a note of the User or Bot OAuth Token. This will be used to authenticate the connector against Slack.
Content Source Configuration
The content source configuration of the connector comprises the following mandatory configuration fields.
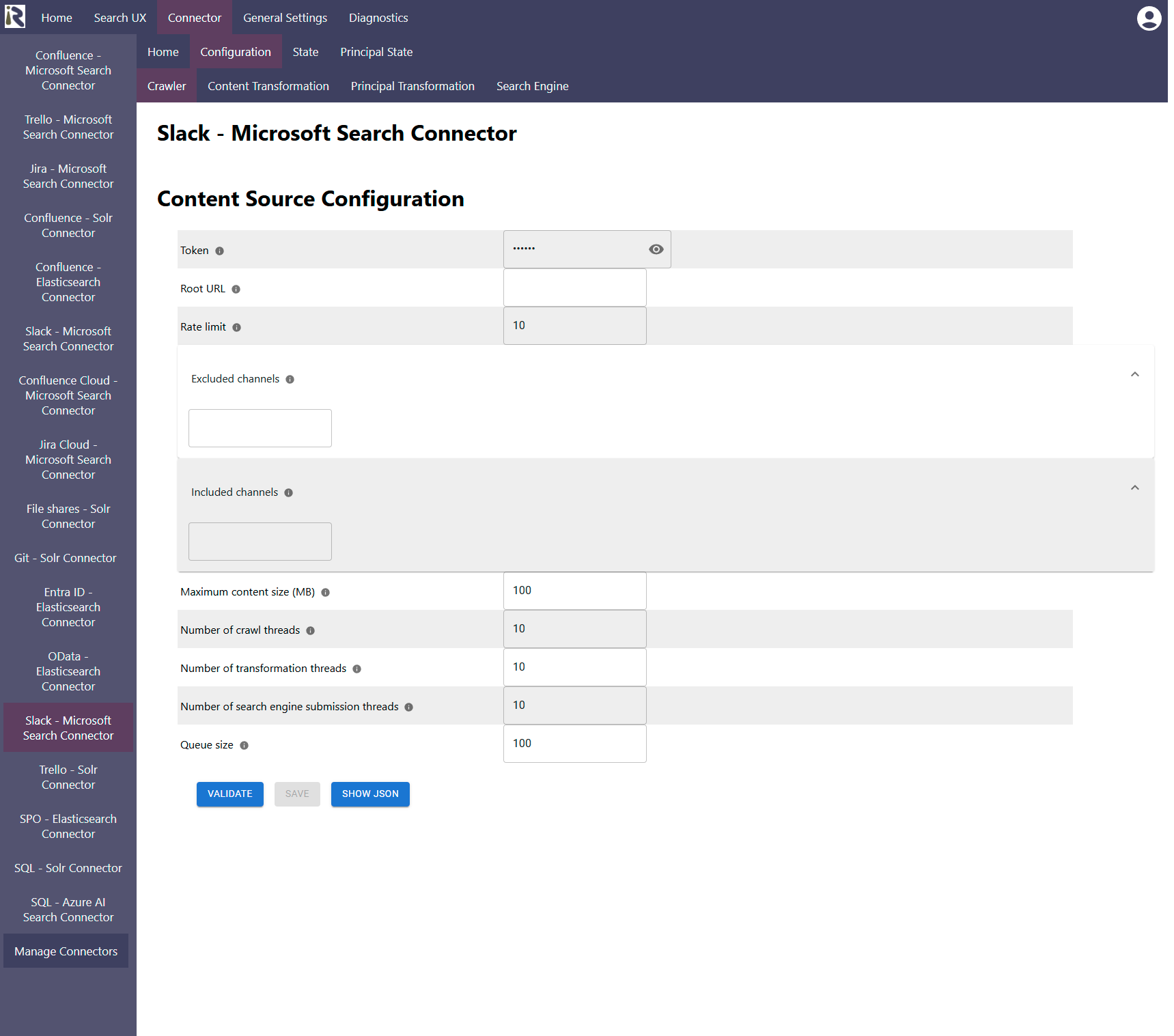
Token: please add the User or Bot OAuth Token from Step 5.d above.
Root URL: please add your tenant url as https://<tenant>.slack.com
This will be used for mandatory calculations in the course of the crawl.Rate limit describes the number of requests per second against the Slack APIs. If this value is chosen as too large, it may cause rate limiting. Please also refer to the Slack API guidelines.
Excluded channels: here you can provide Java regular expressions or channel names to exclude channels from crawling.
Included channels: here you can provide Java regular expressions or channel names to describe channels which should be solely crawled.
The general settings are described at General Crawl Settings and you can leave these with its default values.
After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source. If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Limitations for Incremental Crawls and Recommended Crawl Schedules
Slack does not offer a complete change log. Even though the connector can efficiently detect new messages and attachments, it does not get notified if Slack messages were removed or deleted or updates in threads take place.
Therefore, we recommend to configure incremental crawls to run every 15-30 minutes, principal scans to run twice a day, as well as a weekly full scan to keep the search index in synchronization with the Slack instance. For more information see Crawl Scheduling .