Documentation
Crawl Scheduling
All crawls can run manually, can be triggered via the REST APIs or can be scheduled. In productive scenarios, crawls are usually scheduled via the crawl scheduling mechanisms within the respective connector home views at
https://<host>/admin > Connector > Confluence for Microsoft Search Connector (or similar) > Crawl Schedule
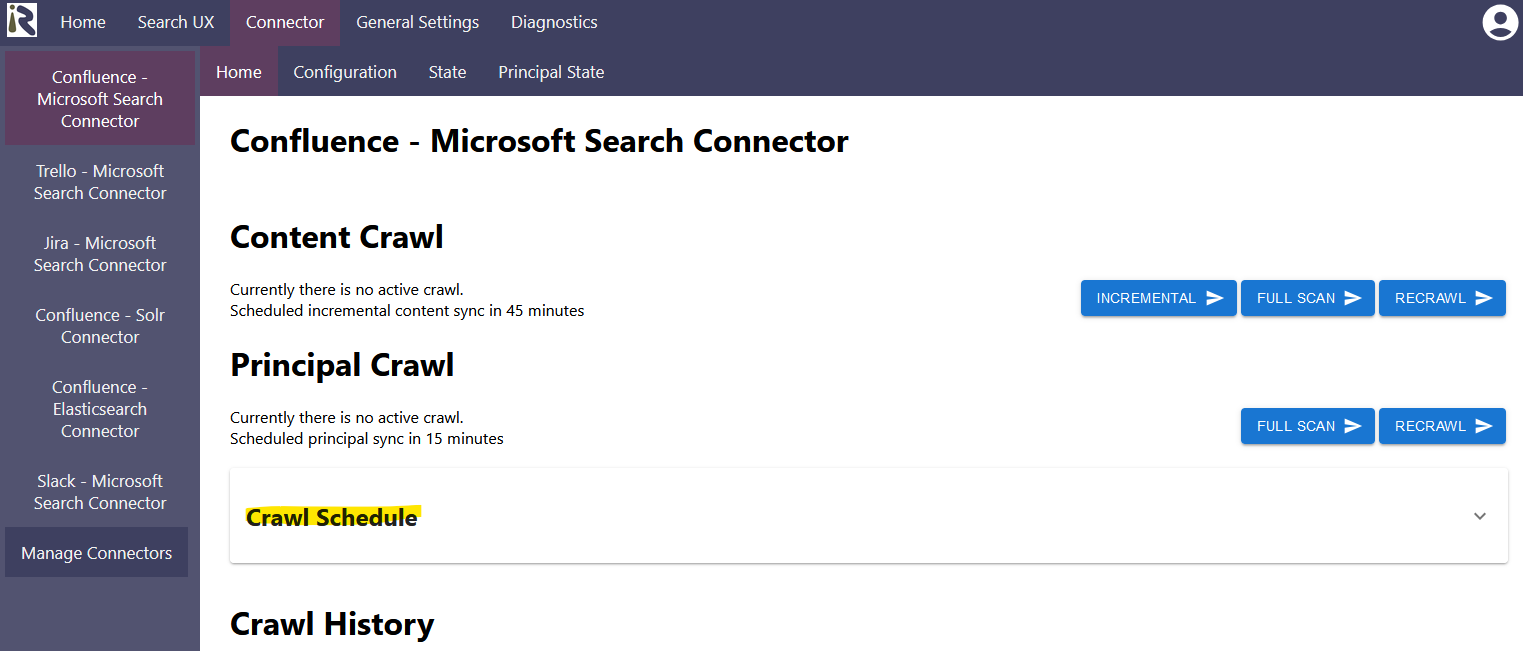
Adding a new Crawl Schedule
Within the dialog click on add.
Click on the tab to open the new schedule
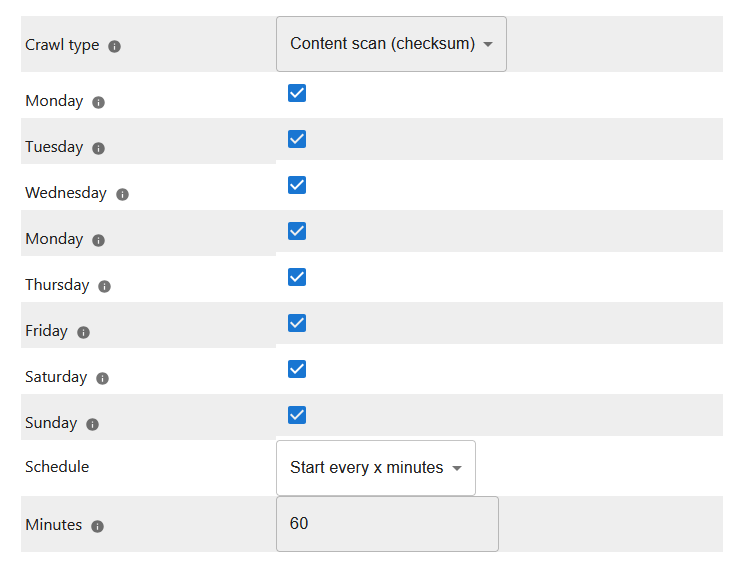
Choose the crawl type. For a description of the crawl types, please confer to Crawl Modes .
Choose the weekdays, this crawl schedule should be active
Choose whether the crawl should run on specific times or every x minutes.
When choosing Start every x minutes, the crawl runs every full hour (relative to 0:00h at the server) modulo the entered minutes.
When choosing specific times, you can enter start times in the format hh:mm. The start times refer to the server time.
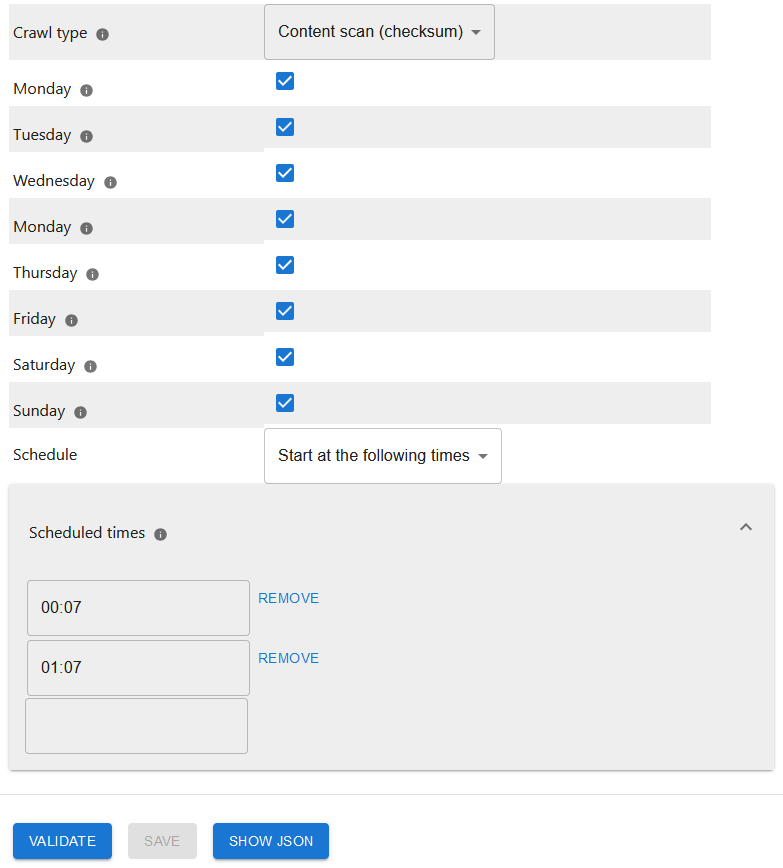
After adding your information click on validate and save. Only then changes to the crawl schedule become active
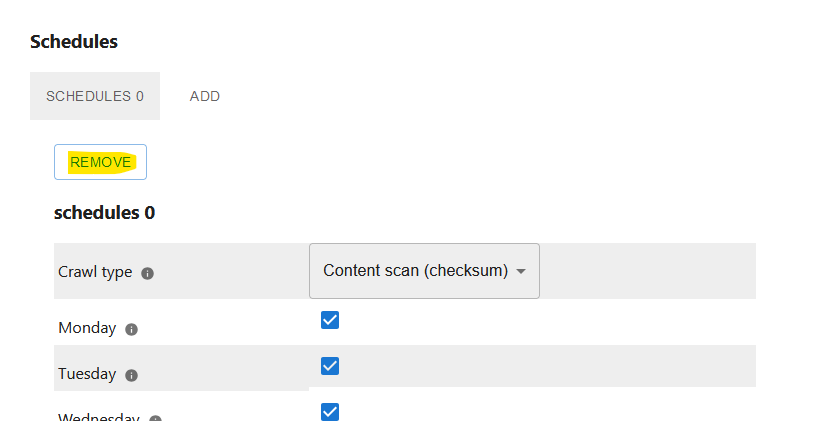
Removing a Crawl Schedule
You can remove a crawl schedule by clicking on the remove button. After validating and saving the new schedule, the crawl schedule becomes inactive.