Documentation
JDBC and SQL Server Connector
For a general introduction to the connector, please refer to https://www.rheininsights.com/en/connectors/sql.php .
SQL Server Configuration
Crawl User
The connector needs a crawl user which needs to have the permissions to connect to the server, as well as to execute the configured queries.
Please note that the connector only supports server authentication. For Microsoft SQL server this means that Windows authentication is not yet supported.
Password Policy
The crawl user must have no password rotation or the password needs to be reset when it changes.
Content Source Configuration
The content source configuration of the connector comprises the following mandatory configuration fields.
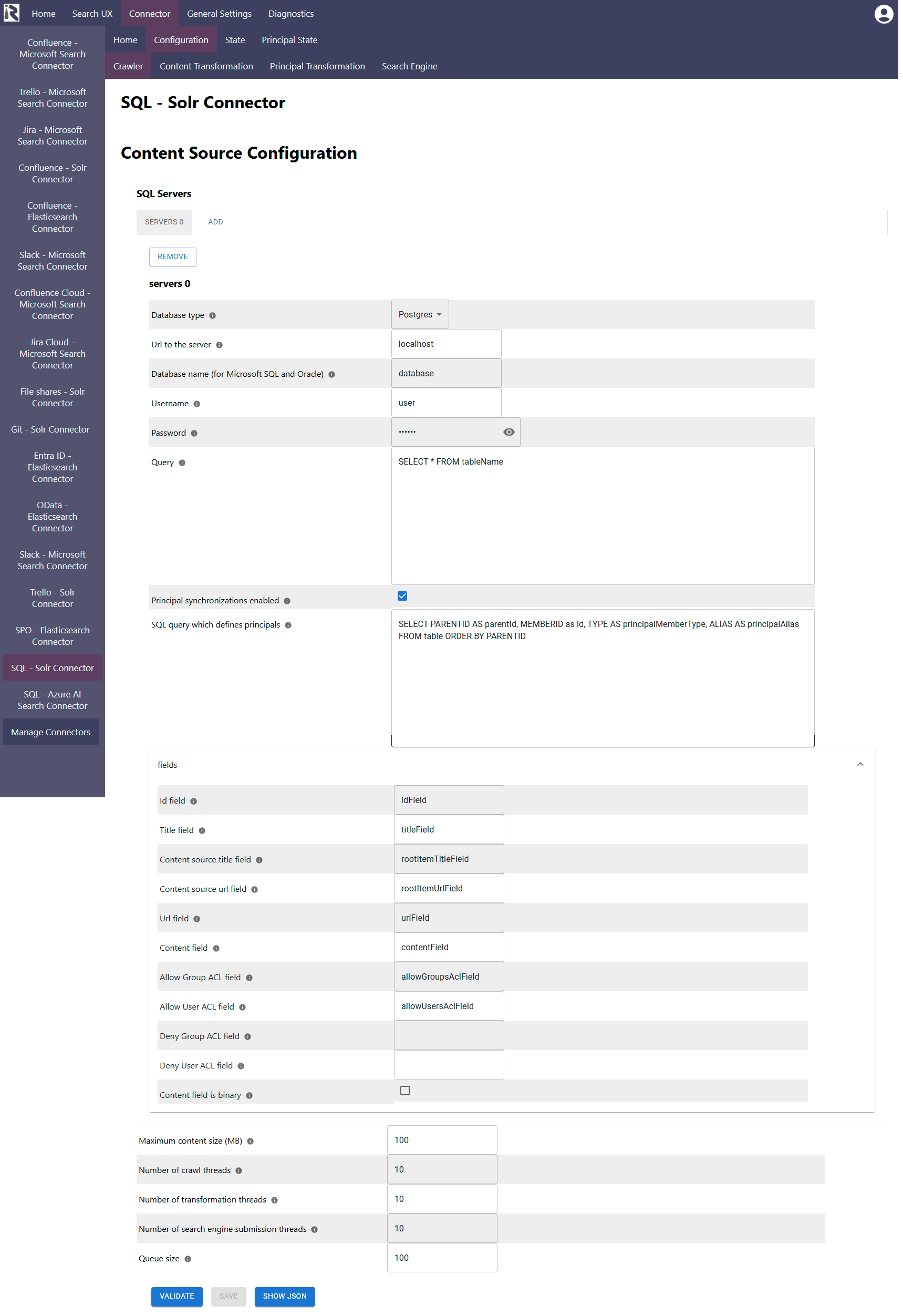
You can manage the SQL servers and queries, you like to use for crawling in the SQL Servers dialog.
Here you can add and remove servers along with the queries, you like to execute
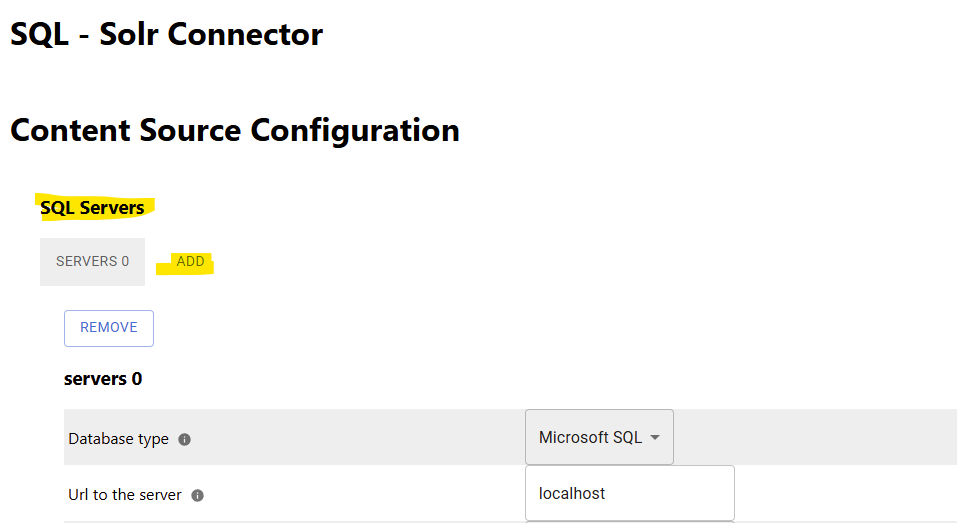
In each “server” dialog you can configure the following:
Database type: please choose which kind of database you like to crawl.
Url to the server: Please add the server url, port and database name of the server, you like to crawl.
For Postgres instances this is “<FQDN>:<Port>/<database>”
For Microsoft SQL this is <FQDN of the instance>:<port>. Please add
Username: is the user name which is used by the connector to crawl the instance. Please see the above for the necessary user permissions.
Password: is the corresponding password for the crawl user
Query: this must be a valid SQL statement which returns results. A query can be arbitrary and leverage tables, views, joins and more.
The connector will execute it once per crawl and iterate over the entire result set. Therefore, please make sure that the query is not a blocking statement which interferes with other processes on this SQL server instance.
Please note that the connector will not consolidate multiple records as one document.
Principal synchronizations enabled: please enable this field if the connector should interpret data from an additional query result as user group relationships.
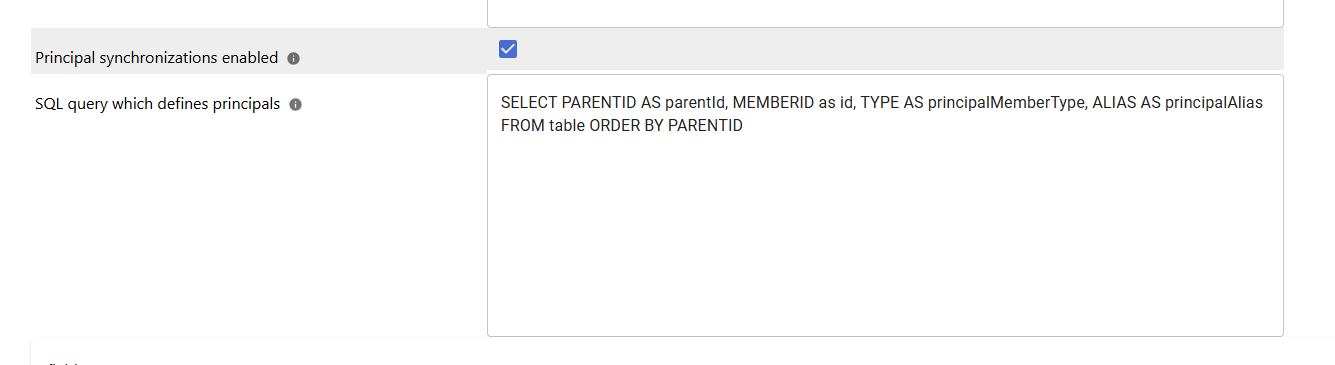
SQL query which defines principals. Please enter a SELECT statement which prepares pairs of ParentIds and MemberIds, such as
”SELECT PARENTID AS parentId, MEMBERID as id, TYPE AS principalMemberType, ALIAS AS principalAlias FROM table ORDER BY PARENTID”
The connector will then construct user (member) - group relationships out of the result set. Each row must contain an additional principalMemberType which is either “user” or “group”, as well as for users a principalAlias, which is ideally a user principal name or e-mail address.The general settings are described at General Crawl Settings and you can leave these with its default values.
Id field: Refers to a field of the result set. It must be a field of the result set which contains a unique key for each record.
Title field: Refers to a field of the result set. It must be a field which is used to retrieve the record’s title for indexing.
Content source title field (optional): Refers to a field of the result set. It must contain the content source’s name.
Content url title field (optional): Refers to a field of the result set. It must contain the content source’s url.
Content field: Refers to a field of the result set. It must contain the string or bytes (see Content field is binary below) which contains the contents which are used for vectorization or text extraction before indexing.
Content field is binary: determines how to interpret the content field. If this checkbox is checked, the content will be sent as a binary document either directly to the search engine or if a text extraction takes place in the content transformation pipeline, then this is used as input.
Allow Group ACL field (optional): Refers to a field of the result set. It can contain one or multiple semicolon-separated group names.
Allow User ACL field (optional): Refers to a field of the result set. It can contain one or multiple semicolon-separated user ids (ideally user principal names, as these must match the filters for secure search).
Allow Deny ACL field (optional): Refers to a field of the result set. It can contain one or multiple semicolon-separated group names for determining who must not be allowed to find the record in search.
Allow deny ACL field (optional): Refers to a field of the result set. It can contain one or multiple semicolon-separated user ids for determining who must not be allowed to find the record in search.
After entering the configuration parameters, click on validate. This validates the content crawl configuration directly against the content source. If there are issues when connecting, the validator will indicate these on the page. Otherwise, you can save the configuration and continue with Content Transformation configuration.
Recommended Crawl Schedules
Depending on your database and requirements, we recommend to run a Full Scan every half day or even more often. Principal crawls should run twice a day. For more information see Crawl Scheduling .