Documentation
- Getting Started
- Deployment

- Technical Prerequisites
- Data Privacy and Routing
- Administration
- Enterprise Search Connectors
- Managing Connectors
- Connector Home View
- Sources
- Content Transformation
- ACL Assigner
- Adjustable Text Extractor
- Data Logger
- Document Classifier
- Document Preview Generation
- Document Splitter
- Document Translation
- Html Token Remover
- Metadata Assigner
- Metadata Extractor
- Metadata Mapper
- Text Extractor
- Vectorizer and Embeddings
- LLM Specific Configurations - Content Transformers
- Security Transformation
- General Crawl Settings
- Performance Considerations
- Crawl Modes
- Crawl Scheduling
- Standard Schema
- State View
- Principal State View
- Search Experiences
- AI and Query Pipelines
- Search Engines
- MCP, Agents and Bot Integrations
- Backup and Restore Concept
- Software Updates and Upgrade
- Releases and Release Notes
Vectorizer and Embeddings
Using embeddings is one of the key ingredients for vector search and Retrieval Augmented Generation (see Retrieval Augmented Generation ). The Vectorizer stage uses an embedding provided by a large language model to generate a vector representations for the given document.
In particular, two vectors will be generated. One for the title field and one for the document contents.
The resulting vector(s) will later-on be indexed along with the “normal” document metadata and contents. This means, the vectors will be added as additional fields to the document before indexing.
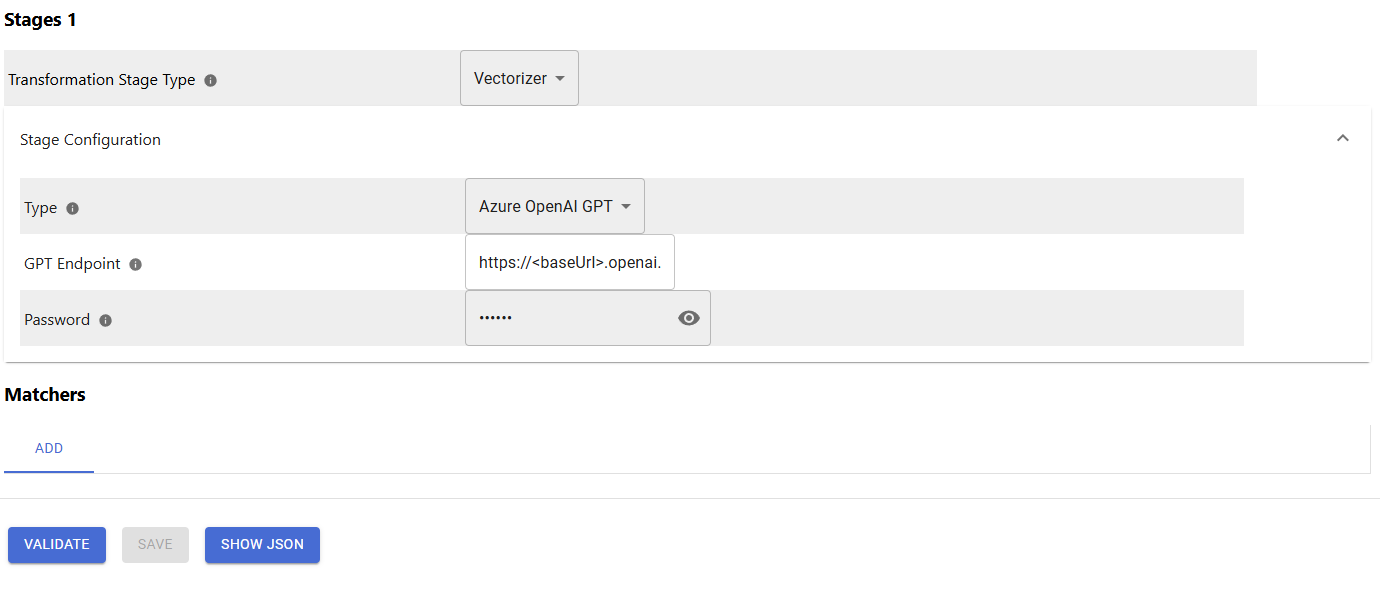
Configuration Parameters
See the parameter description at LLM Specific Configurations - Content Transformers