Documentation
- Getting Started
- Deployment

- Technical Prerequisites
- Data Privacy and Routing
- Administration
- Enterprise Search Connectors
- Managing Connectors
- Connector Home View
- Sources
- Content Transformation
- ACL Assigner
- Adjustable Text Extractor
- Data Logger
- Document Classifier
- Document Preview Generation
- Document Splitter
- Document Translation
- Html Token Remover
- Metadata Assigner
- Metadata Extractor
- Metadata Mapper
- Text Extractor
- Vectorizer and Embeddings
- LLM Specific Configurations - Content Transformers
- Security Transformation
- General Crawl Settings
- Performance Considerations
- Crawl Modes
- Crawl Scheduling
- Standard Schema
- State View
- Principal State View
- Search Experiences
- AI and Query Pipelines
- Search Engines
- MCP, Agents and Bot Integrations
- Backup and Restore Concept
- Software Updates and Upgrade
- Releases and Release Notes
Document Splitter
This stage splits textual contents into separate documents. Document splitting is very important for generating good answers for retrieval augmented generation, as relatively long documents can normally not be processed in prompts. On the other hand, answers to questions are seldomly spread across multiple paragraphs but can be found in one or multiple sections. Thus, normally it is executed after a Text Extractor Stage Text Extractor .
Therefore, within the configuration, you can offer HTML tags to detect good splitting marks, such as paragraphs. Also, you can add Regexes to find good titles for the resulting new documents. Also, it offers regexes to find according URLs, such as anchors on the page, to serve as URLs for the resulting documents. All of this is not mandatory, as the splitter has a maximum content length as fallback.
The result is a sequence of smaller documents, which can also be found in the document state, cf. State View . All of these documents have the itemType “split”. Also, the original document is kept and indexed. The splitted documents furthermore will be linked to the original document and will be updated when the original document changes.
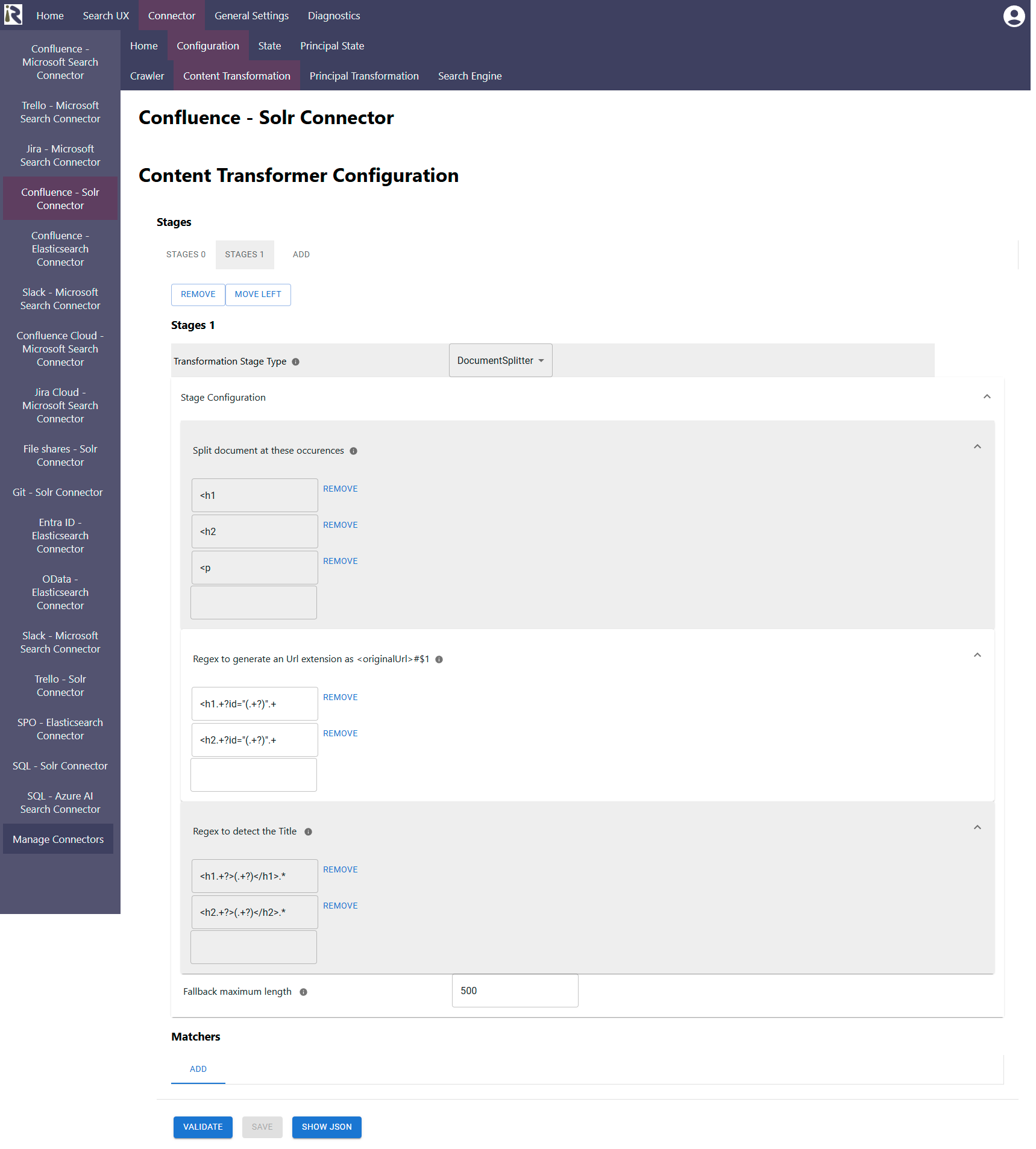
Configuration Parameters
Split document at these occurrences: please add one or more tags or strings which should serve as a splitting marker for documents.
The stage will split the text at each of these occurrences. If you add<h1 and <h2
then a text<h1>hello world</h1>…<h2>I am here</h2>…
becomes
Document1 body:
<h1>hello world</h1>…
Document2 body:
<h2>I am here</h2>…
Regex to generate an Url extension: Here add a regular expression in Java syntax to detect potential anchor links or URLs on the page. The generated URL will be used as an anchor to the original document’s URL as follows.
Suppose the original URL is https://en.wikipedia.org/wiki/"Hello,_World!"_program and the page contains<h2 id="History">History</h2>
Then applying the following URL detection
<h2.+?id="(.+?)".+
results in the following generated document URL for the splitted document
https://en.wikipedia.org/wiki/"Hello,_World!"_program#History
Regex to detect the title: This parameter will be used to automatically generate a title for the splitted document. The approach works as follows.
Suppose the original URL is https://en.wikipedia.org/wiki/"Hello,_World!"_program and the page contains<h2 id="History">History</h2>
Then applying the following title detection
<h2.+?>(.+?)</h2>
results in the following generated title for the splitted document is
History
Fallback maximum length: determines how many characters a splitted document should become at most. If between two of the occurrences in 1. lie more than this amount of characters, the document will be splitted at the next end of a sentence after this amount of characters.