Documentation
Microsoft Search - Indexing Configuration
Technical Prerequisites
For indexing, you need to register an Entra Id application as follows:
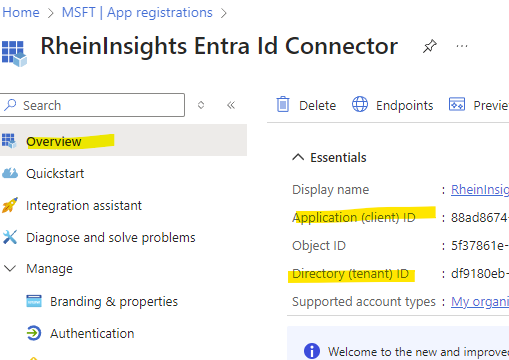
Navigate to https://portal.azure.com
Open Entra Id
Open App registrations
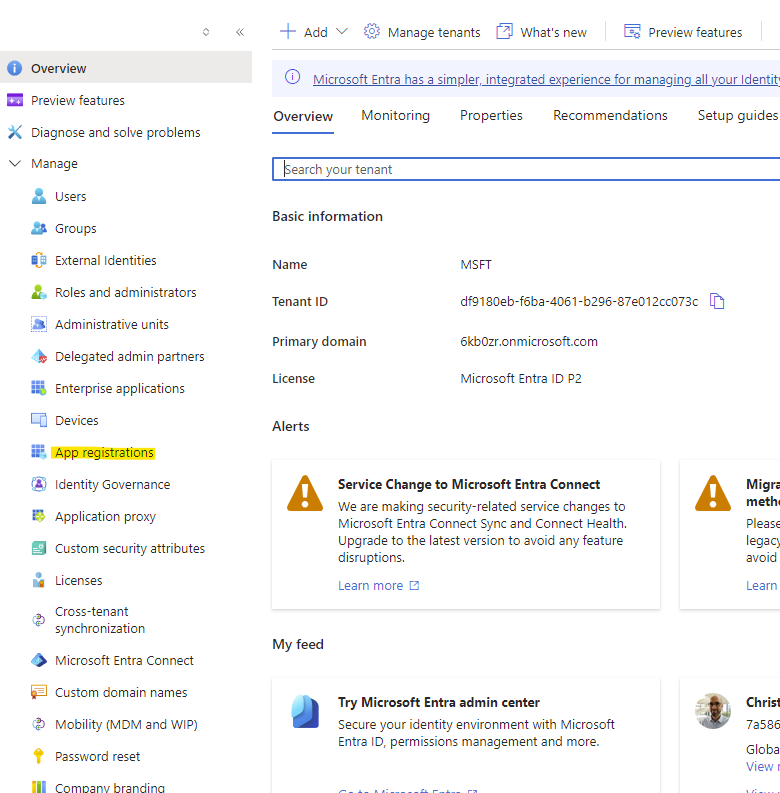
Click on New registration
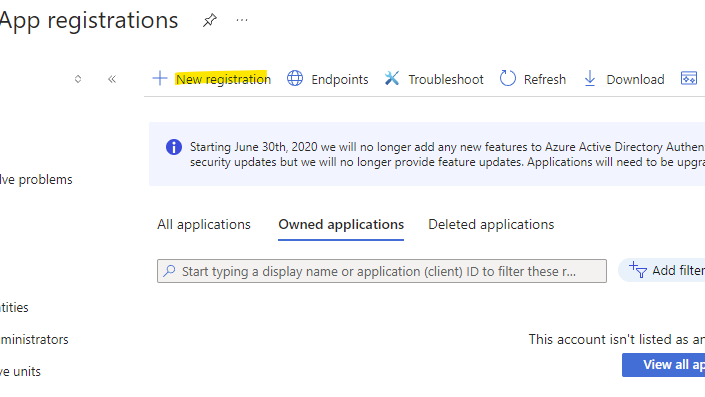
Give it a name
Click on Register
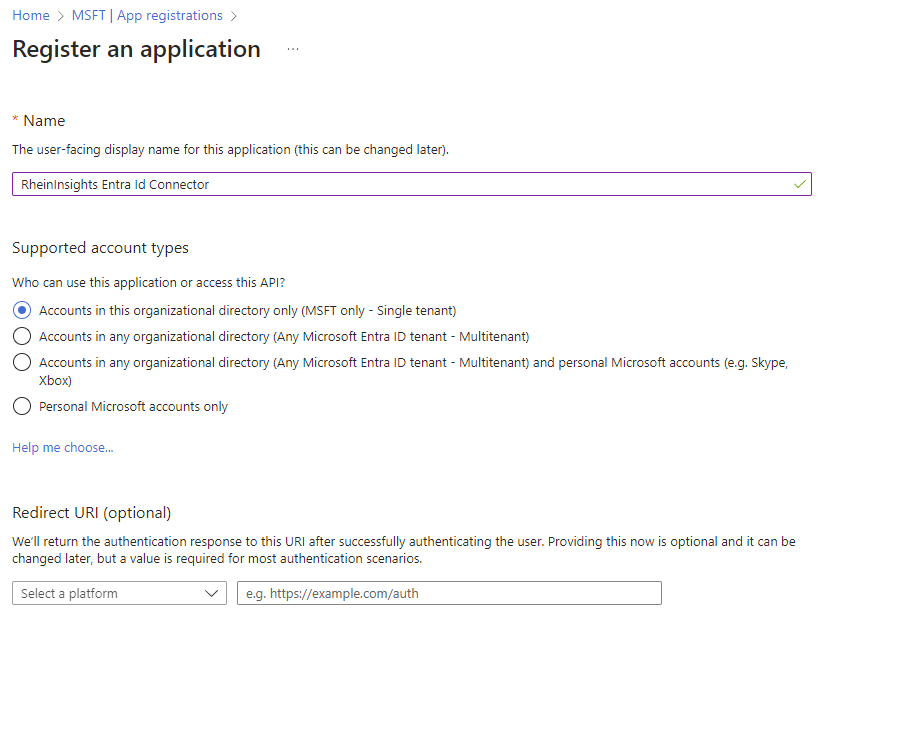
Click on API permissions
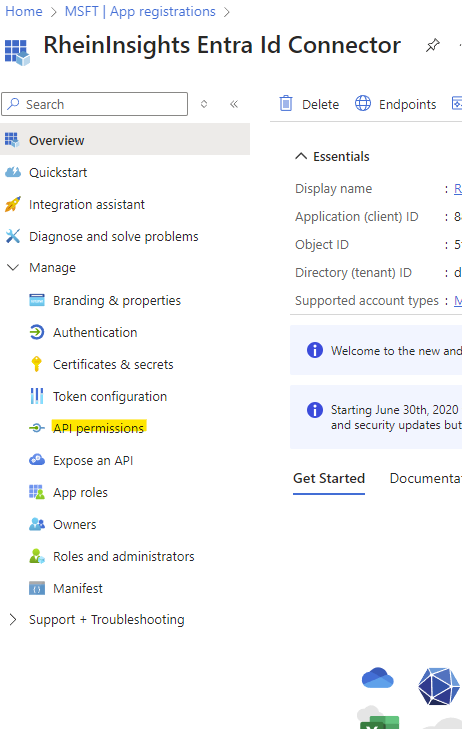
Add a Permission
Click on Microsoft Graph

Choose Application Permissions
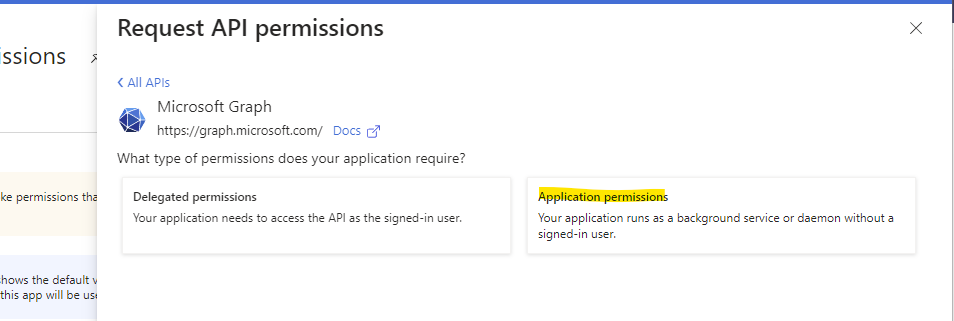
Please search for the following permissions and check the respective boxes:
Search for ExternalConnection.ReadWrite.All and check the Box
Search for ExternalItem.ReadWrite.All and check the box
Search for Users.Read.All and check the box
Click on Add permissions
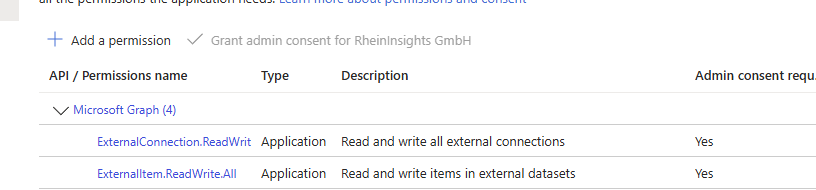
Grant the consent
Got to certificates and secrets
Generate a new Client Secret
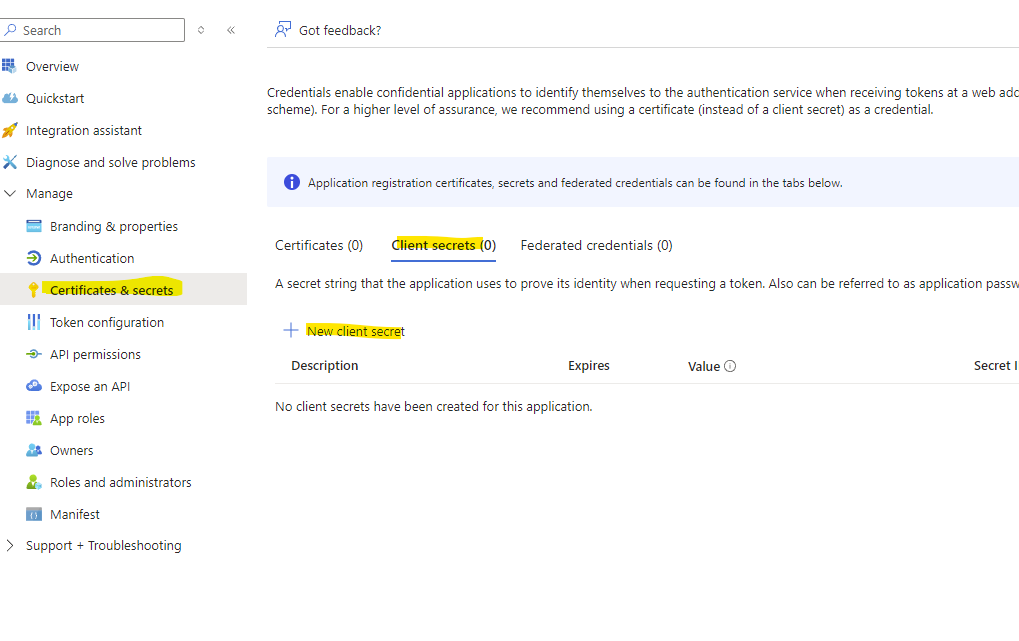
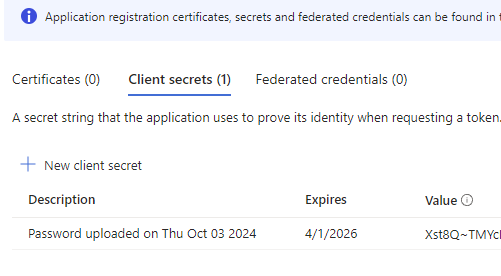
Give it a name and an expiration date
Create the secret
Then make a note of the value
Click on Overview and make a note of client Id and tenant Id
Configuration
You can access this dialog as part of the connector configuration, if the connector has Microsoft Search as target.
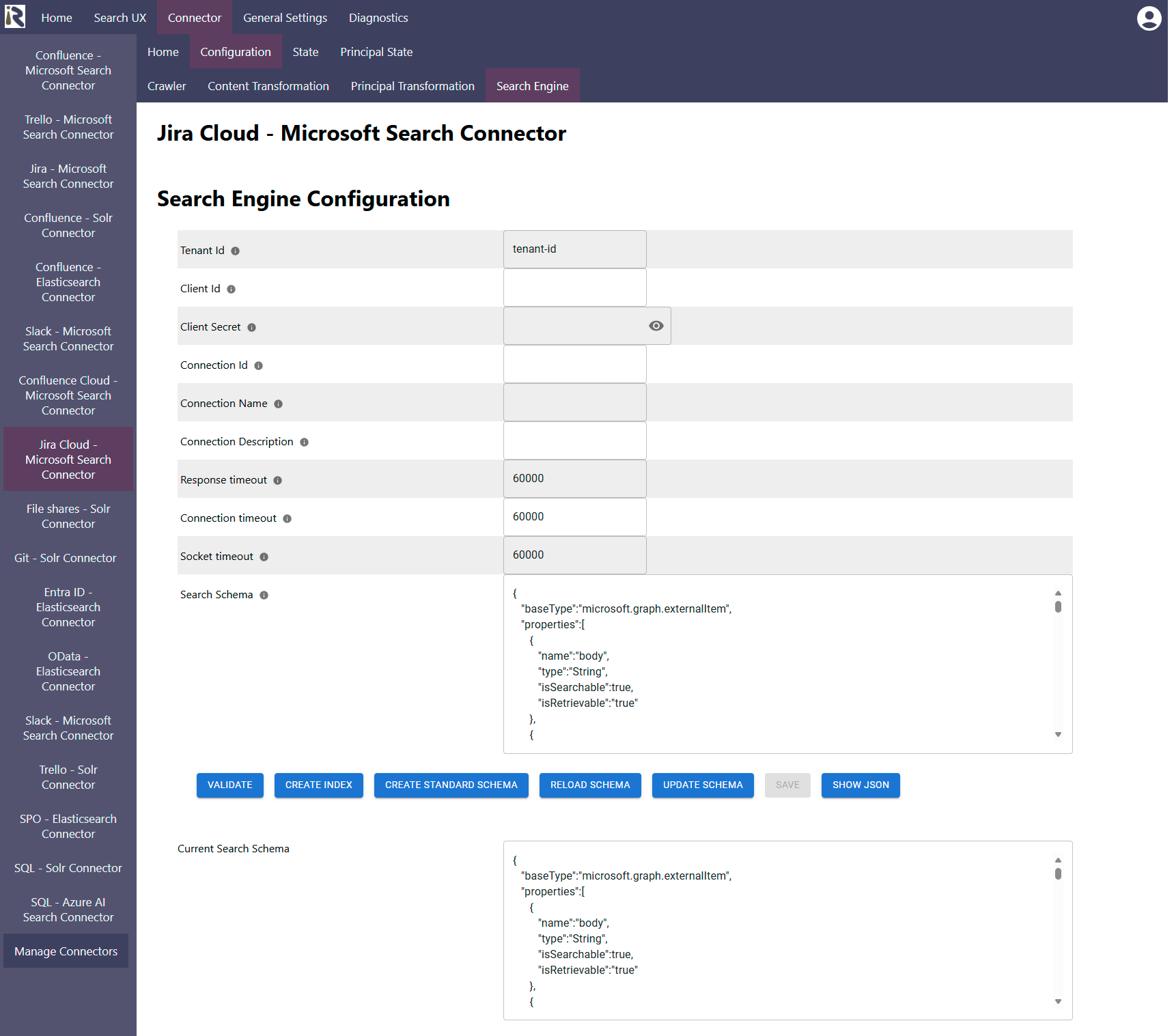
Tenant Id: is the tenant id from the app registration above.
Client Id: is the client id from the app registration above
Client secret: is the secret from the app registration above
Connection Id: Is the name of the external connection where the connector should index the documents into.
Connection description: this is the description which the connector uses during index creation. For normal operations, this field is not needed.
Response timeout: determines the timeout when waiting for responses in milliseconds.
Connection timeout: determines the timeout when waiting for connections to the instance in milliseconds.
Socket timeout: determines the timeout when waiting for connections to the instance in milliseconds.
Vector field for title. If you use vector search for the vectorization stages), then this field is used to push the vectorized title into.
If you configure the search engine for querying data (cf. Search Experience and Query Pipelines ), then this field is used for issuing vector queries.Vector field for body. If you use vector search, then this field is used to push the vectorized body into.
If you configure the search engine for querying data, then this field is used for issuing vector queries.Filters (aka refiners aka aggregations)
Within this dialog you can add and remove filters. This does not mean that filters will be shown in the search interface right away but it is needed to tell the search engine to return calculated filters.
Filter type: defines if this is a term filter (such as for file types), range filters (such as for prices) or date filters.
Fieldname: is the name of the field which the filter should be computed for.
Number of values to show: for term filters this defines how many values should be returned.
Sorting: defines if the filter buckets should be sorted based on the document frequency (number of results) or lexicographically
Sort direction: if sorting should be descending or ascending (based on the ordering type in e.)
When finished with setting these fields, click on validate and save. If you observe any issues, then the validator will let you know or you can find more insights in the log files.
Managing the Search Schema
The Search schema field and also the controls are described at Index Creation and Management .
The connector comes with a standard schema, which you can manage from the configuration dialog.
There is no need for a principal index, as Microsoft Search comes with its own principal store.