Documentation
Azure AI Search - Query Configuration
You can access this dialog via Search UX and by adding an Azure AI Search instance as search engine.
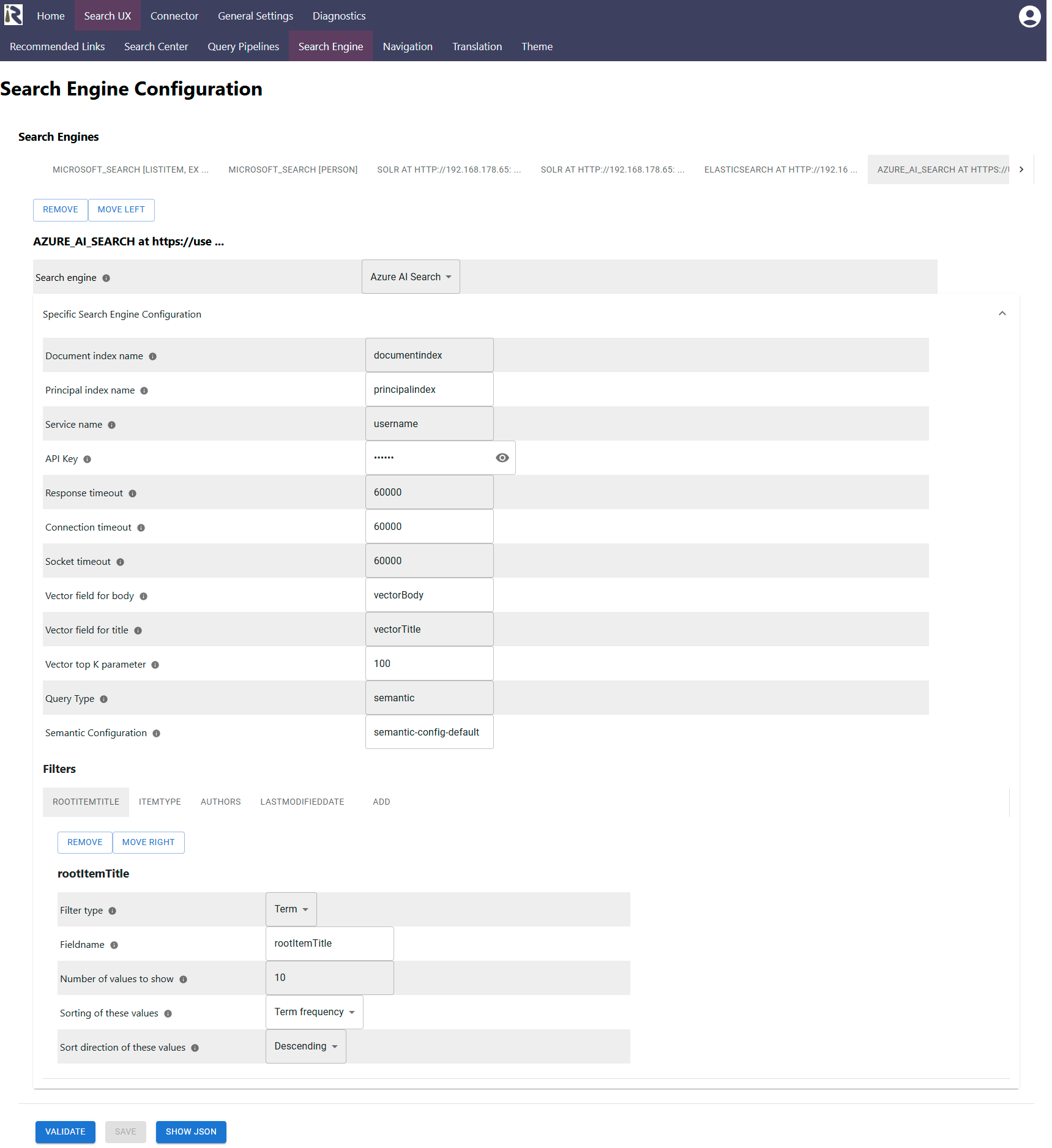
Document index name: this is the name of the document index.
Principal index name: this is the name of the principal index. The principal index is where the connector stored user-group relationships and which is used to construct the ACL entries for the user.
Service name: This is the name of the service as part of https://[service name].search.windows.net.
API Key: is the API key as extracted in Step 2 in the prerequisites above.
Response timeout: determines the timeout when waiting for Azure AI Search responses in milliseconds.
Connection timeout: determines the timeout when waiting for connections to Azure AI Search in milliseconds.
Socket timeout: determines the timeout when waiting for connections to Azure AI Search in milliseconds.
Vector field for body. This is the second field, which will be used for vector search, if an embedding is found (see the query pipeline documentation at AI and Query Pipelines ).
Vector field for title. This is the first field, which will be used for vector search, if an embedding is found (see the query pipeline documentation at AI and Query Pipelines ).
Vector top k parameter for vector search: this parameter is relevant for vector search and defines how many results will be returned when having a vector search.
Query Type: For vector search, you can configure the query type as described at https://learn.microsoft.com/en-us/azure/search/hybrid-search-overview
Query configuration: this is the query configuration as given in the search schema definition.
Filters (aka refiners aka aggregations)
Within this dialog you can add and remove filters. This does not mean that filters will be shown in the search interface right away but it is needed to tell the search engine to return calculated filters.
Filter type: defines if this is a term filter (such as for file types), range filters (such as for prices) or date filters.
Fieldname: is the name of the field which the filter should be computed for.
Number of values to show: for term filters this defines how many values should be returned.
Sorting: defines if the filter buckets should be sorted based on the document frequency (number of results) or lexicographically
Sort direction: if sorting should be descending or ascending (based on the ordering type in e.)
When finished with setting these fields, click on validate and save. If you observe any issues, then the validator will let you know or you can find more insights in the log files.
Vector Search Dimensions
When using vector search, you need to make sure that the embeddings you use in the query, as well as in the content transformation pipeline have exactly the same dimension as the index fields vector body and vector title. Otherwise indexing or querying the index will fail.