
Unsere Dokumentenverarbeitung kurz erklärt
In unserer RheinInsights Retrieval Suite können mehrere Konnektoren konfiguriert werden. Aber Sie können
für jeden konfigurierten Konnektor eine eigenen Verarbeitungspipelines definieren.
Genauer gesagt eine Pipeline für die Dokumentenverarbeitung und eine für die Prozessierung der Security-Principals.
Denn all unsere Konnektoren sind so geschrieben, dass sie ein standardisiertes Metadatenmodell befüllen. Damit hoffen wir
Ihre Integrations-Aufwände deutlich zu senken. Darüber hinaus, gibt es aber viele Use-Cases, wo
eine weitere Transformation der Dokumentdaten notwendig ist. Dies geschieht dann in der Verarbeitungspipeline und dort in verschiedenen
sogenannten Stages.
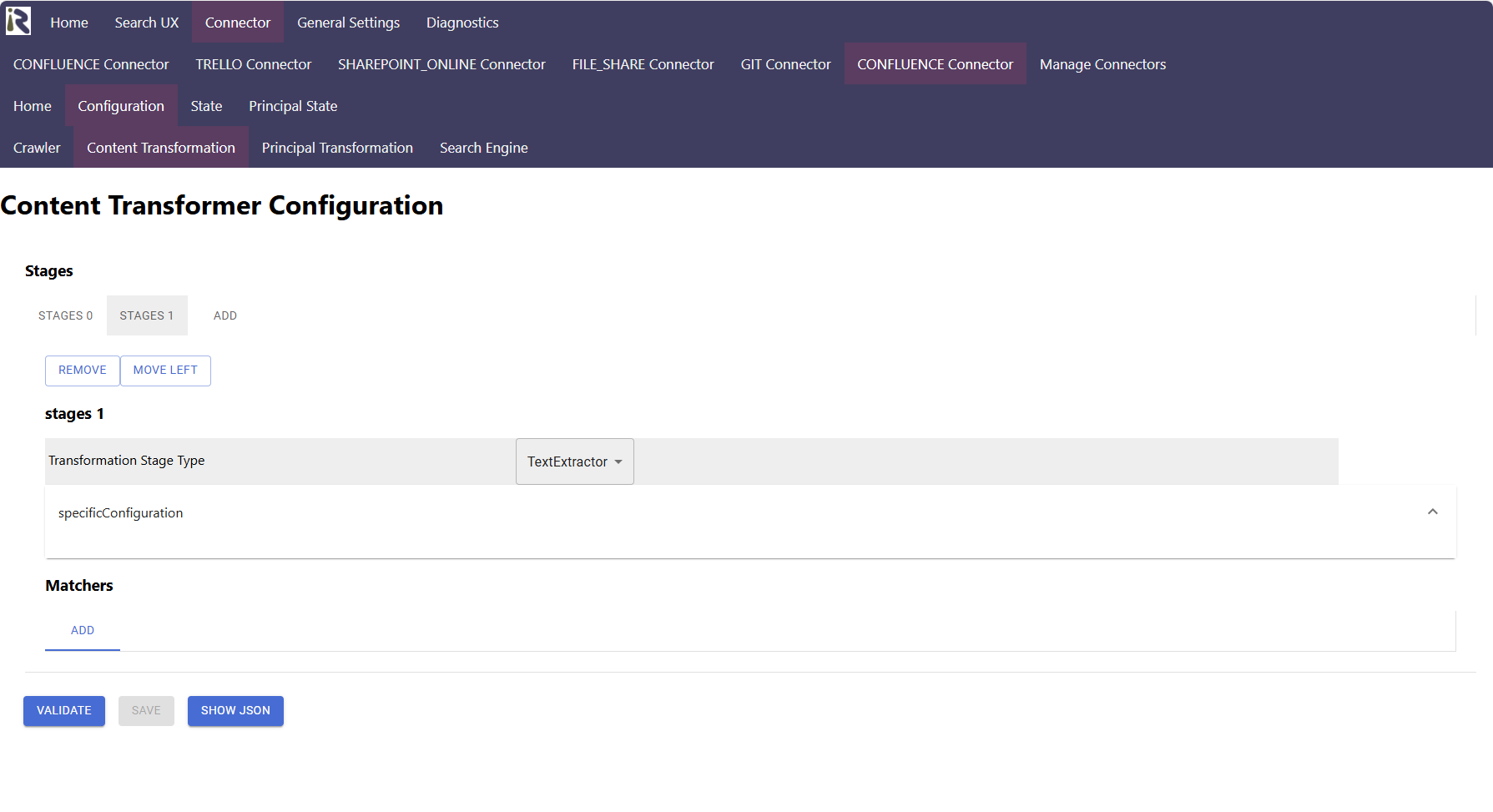
Unsere Suite enthält eine Reihe eingebauter Stages. Daher können Sie relativ einfach entscheiden, welche Stages in welcher Reihenfolge ausgeführt werden. Darüber hinaus können Sie konfigurieren, wann welche Stage, basierend auf den Metadaten eines Dokuments, ausgeführt wird.
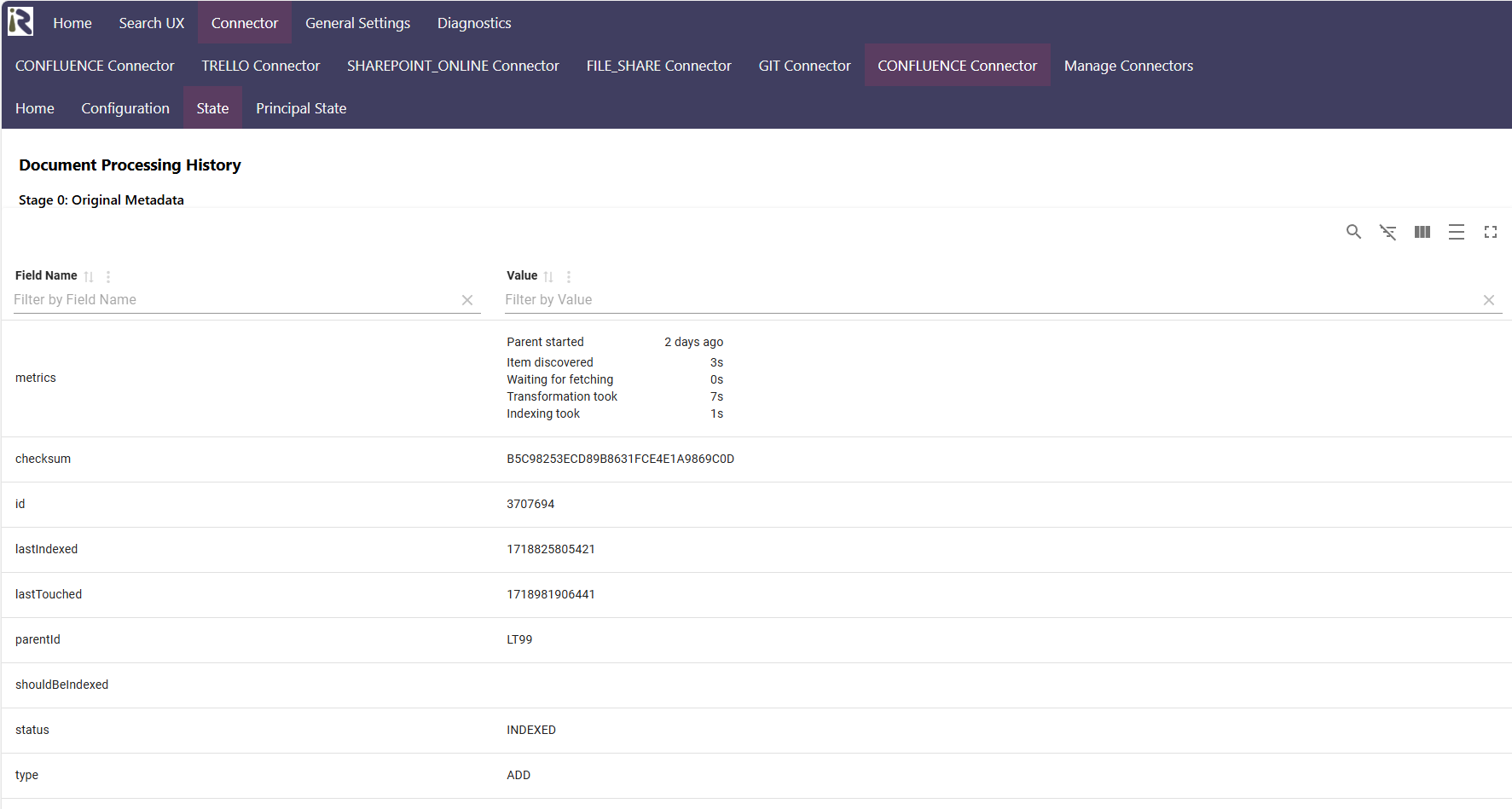
Verarbeitungsergebnisse anzeigen lassen
Wir sind Entwickler und wissen, wie wichtig es ist, zu sehen, ob eine Pipeline das tut, was man möchte. Daher zeigt unsere State-View sämtliche Dokumente an. In der Detailansicht sieht man die Metadaten des Originaldokuments. Wenn das Dokument durch die Verarbeitungspipeline verändert wurde, zeigt diese Sicht auch an, welche Metadaten transformiert wurden. Dies ermöglicht ein zügiges Verständnis, ob die Pipeline das tut, was sie soll und eine schnellere Integration in Ihre Suche.
Features
- Einfach zu konfigurieren
- Eine Dokumenten-, sowie eine Security-Principal-Pipeline je Konnektorinstanz
- Vorgefertigte Verarbeitungs-Stages
- Flexible Konfiguration, abhängig von Ihrem Use Case
Unsere Verarbeitungsstages sind
- Metadaten-Mapping
- Metadaten-Zuweisung
- Dokument-Splitting
- Dokumentenkategorisierung
- Textextraktion
- und mehr
Möchten Sie loslegen?
Registrieren Sie sich kostenlos in unserem Kundenportal, erstellen Sie eine kostenlose Demolizenz und laden Sie unsere RheinInsights Retrieval Suite herunter.