
Document Processing in a Nutshell
Each connector can use its own processing pipelines. Actually, one for the document processing and one for the principal processing. While all connectors come with standartized metadata which reduce integration costs, sometimes there is the need to further process documents prior to indexing.
Our Suite comes with a range of out of the box stages. You can decide, which stages are executed in which order. Furthermore, you can decide if a stage is executed based on the document's metadata.
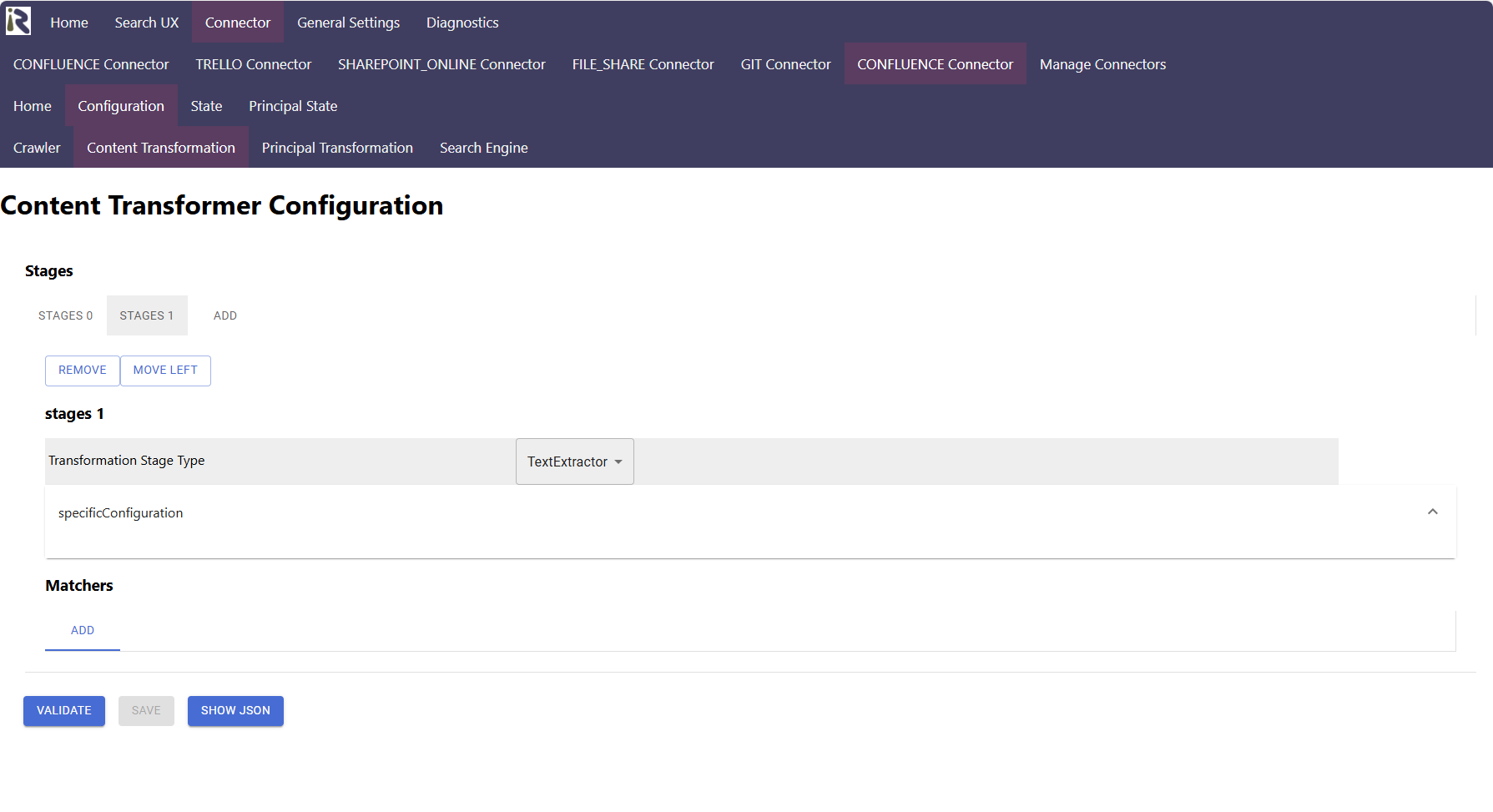
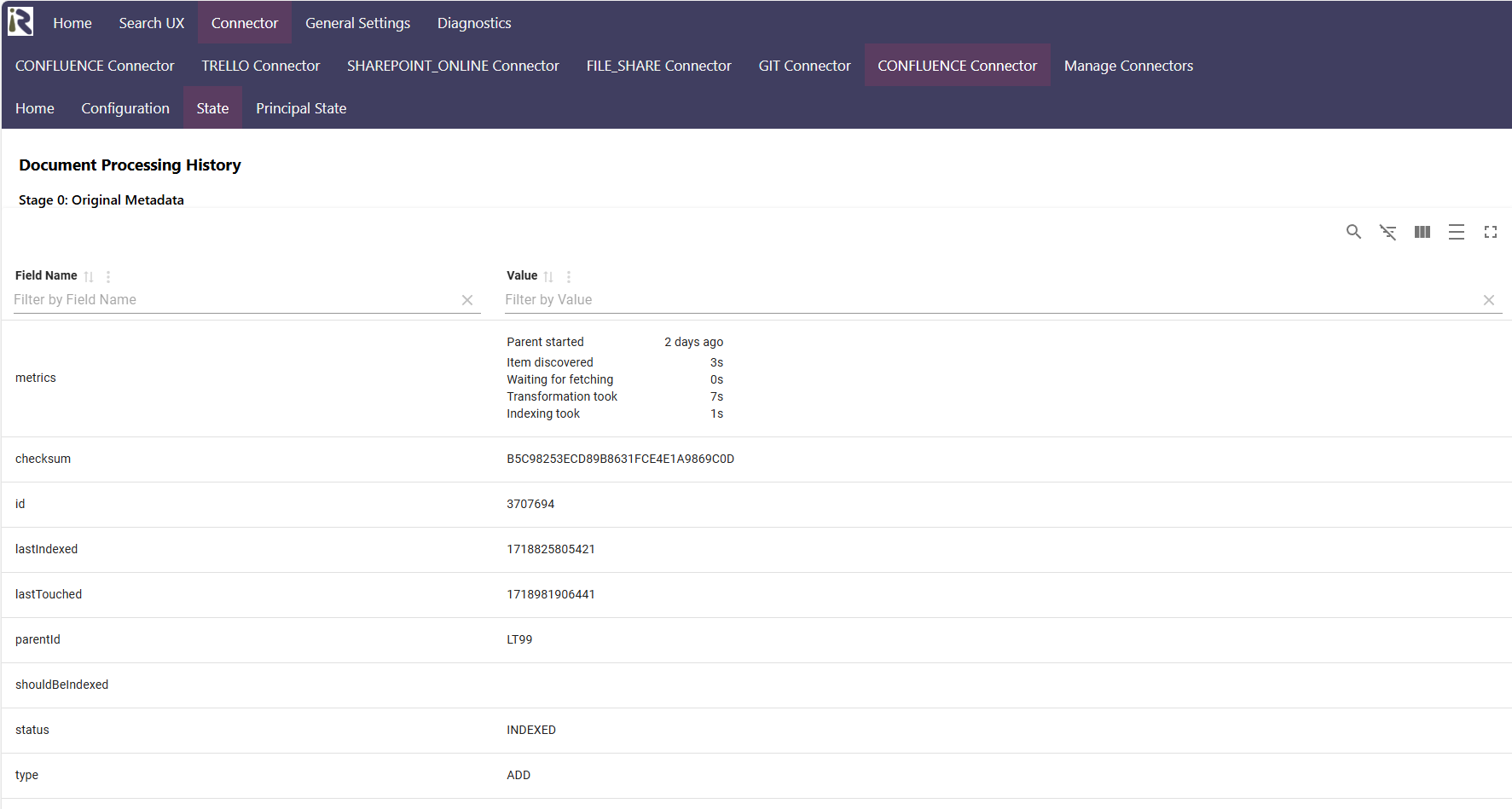
Viewing the Processed Data
We are developers and know how important it is to see if your pipeline is doing what you expect. Therefore, our state view shows the original document metadata. Moreover, it highlights how each stage transformed the metadata further. This allows for faster integrations of your search application.
Features
- Easy to configure
- One document and one principal processing pipeline per connector instance
- Out of the box stages
- Flexible configuration depeding on your use case
Stages include
- Metadata mapping
- Metadata assignment
- Document splitting
- Document categorization
- Content extraction
- and more

Getting started with a trial?
Register for free in our customer portal, create a free demo license and download our RheinInsights Retrieval Suite.