Translations as Part of Modern LLM Pipelines
December 15, 2024
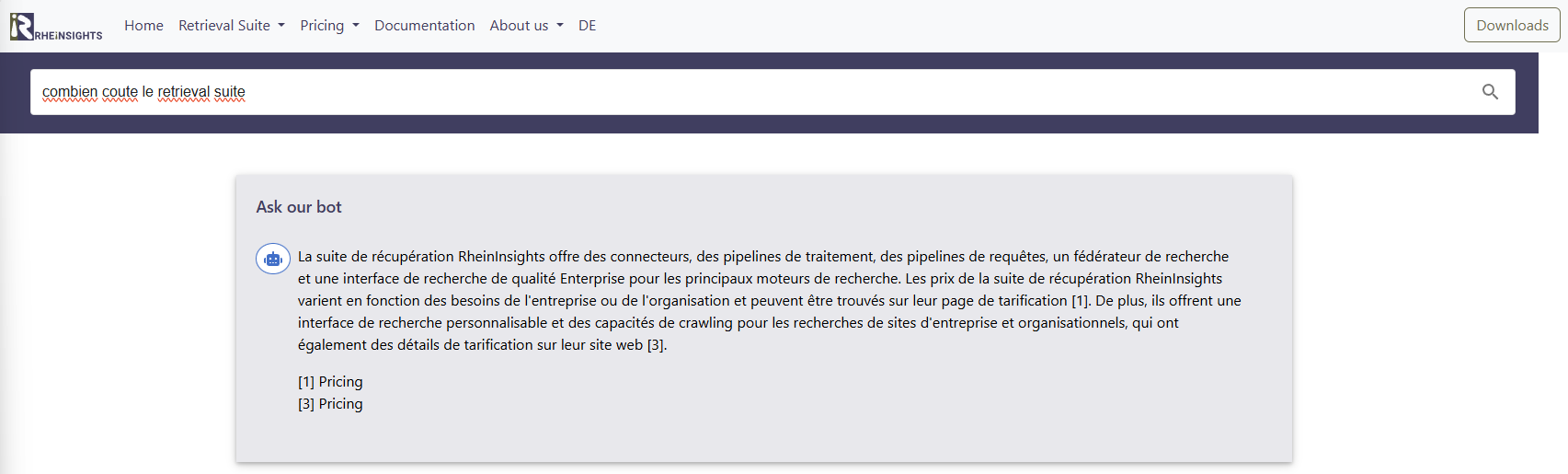
At RheinInsights.com, we experimented with answering non-English and non-German inputs in the original language, even though there are no particular language pages available. How does this work with the large language model and vector search in question and how does the query pipeline look like?
Our Approach
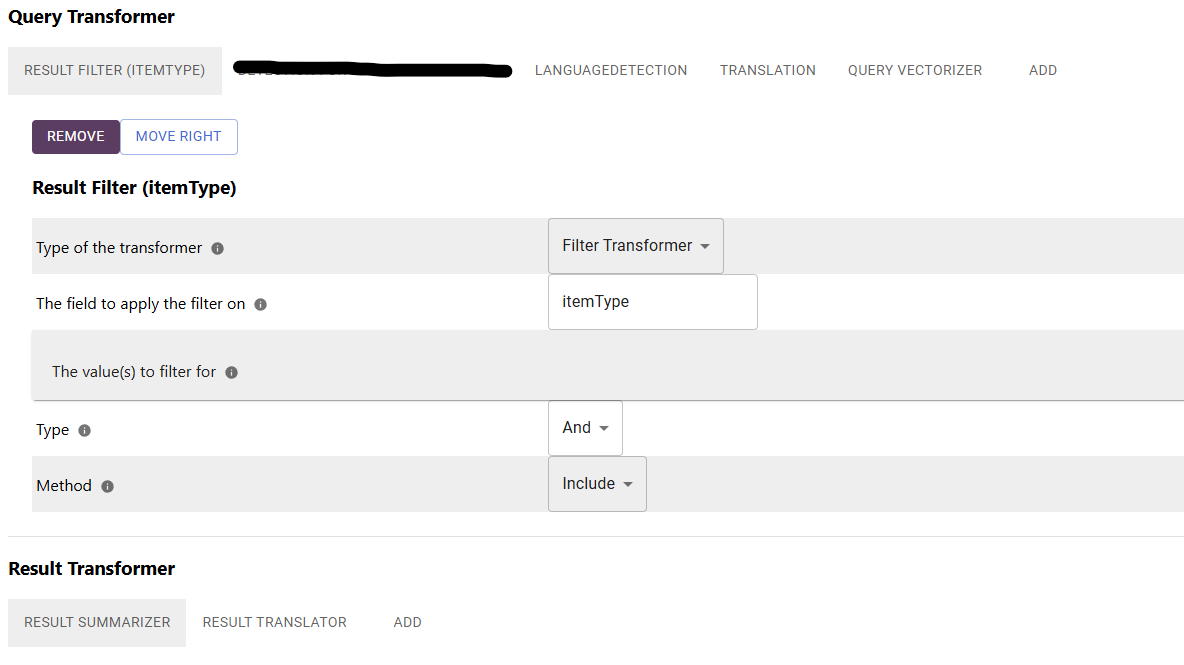
The approach is quite simple and easily implemented with the RheinInsights Retrieval Suite. We define a query pipeline which generally performs the following query transformation steps:
Result Filter. Adding a filter for specific result types (in our case we filter for documents which were cracked open and splitted apart).
Language Detection. Here we detect the input language, in our case an Apache Tika-based language detection is generally sufficient and a bit faster than using an LLM.
Translation. Here we translate the query if the detected input language is neither German nor English. The translation is done using an LLM, such as GPT or OpenLlama.
Query Vectorizer. The translated (English) input query finally is vectorized and sent to the search index.
Then on the way back, the search results are transformed with the following result transformation steps:
Result summarization to conclude the retrieval augmented generation portion of our pipeline. This generates an English answer for the input query based on the retrieved search results.
Translation of the output back into the input language.
Below we show how this pipeline looks like.
Please note, when using a reasonably fast large language model, such as GPT-3.5-turbo, the translation portion is barely notable, unless the generated texts are extremely long.