Übersetzung als Teil unserer Query-Pipeline
Dezember 2024
Bei http://RheinInsights.com haben wir damit experimentiert, nicht-englische und nicht-deutsche Eingaben in der gestellten Sprache zu beantworten, obwohl keine Seiten in bestimmten Sprachen verfügbar sind. Wie kann man dies mit einem Large Language Model (LLM) und einer Vektorsuche abbilden und wie sieht die entsprechende Query-Pipeline aus?
Unser Ansatz
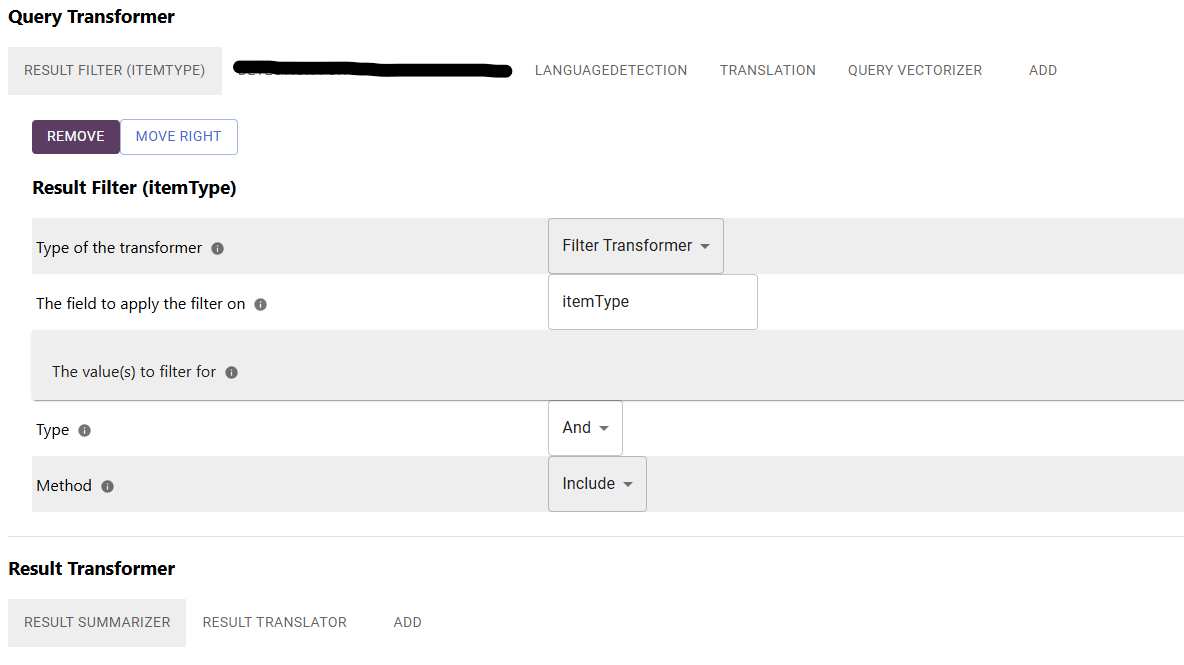
Der Ansatz ist im Prinzip recht geradlinig und mit der RheinInsights Retrieval Suite relativ leicht umzusetzen. Wir konfigurieren eine Query-Pipeline, die folgenden Transformations-Schritte ausführt:
Ergebnisfilter. Hinzufügen eines Filters für bestimmte Ergebnistypen (in unserem Fall filtern wir nur auf Dokumente, welche wir vorher in Fragmente aufgespalten haben).
Spracherkennung. Hier erkennen wir die Eingabesprache. Hier ist eine auf Apache Tika-basierende Spracherkennung ausreichend und zudem etwas schneller als die Verwendung eines LLMs.
Übersetzung. Hier übersetzen wir die Nutzer-Query. Dies geschieht immer dann, wenn die erkannte Eingabesprache weder Deutsch noch Englisch ist. Die Übersetzung erfolgt über ein LLM, wie zum Beispiel GPT oder OpenLlama.
Abfragevektorisierer. Die übersetzte (englische) Query wird schließlich vektorisiert und an den Suchindex gesendet.
Die Suchtreffer werden auf dem Weg zurück zum Nutzer wie folgt transformiert:
Ergebniszusammenfassung als letzten Schritte des RAG-Anteils unserer Query-Pipeline. Hier wird auf Grundlage der Suchergebnisse und der Query eine Antwort generiert.
Übersetzung des Ergebnisses in die ursprüngliche Eingabesprache.
Nachfolgend zeigen wir, wie diese Pipeline aussieht.
Bitte beachten Sie, dass bei Verwendung eines relativ schnellen großen Sprachmodells wie GPT-3.5-turbo der Übersetzungsanteil kaum wahrnehmbar ist, es sei denn, die generierten Texte sind extrem lang.