Retrieval Augmented Generation with Azure AI Search and Atlassian Confluence
10. February 2025
Atlassian Confluence is a great wiki and collaboration platform. Many organizations use it to create living documentation (see e.g. Wikipedia). In other words, documentation that is not handed over to its fate after it has been written down once, but is continually updated and kept up to date. Therefore, it is a valuable source for enterprise search and Q&A bots.
The processing process for Retrieval Augmented Generation is outlined in the following diagram.
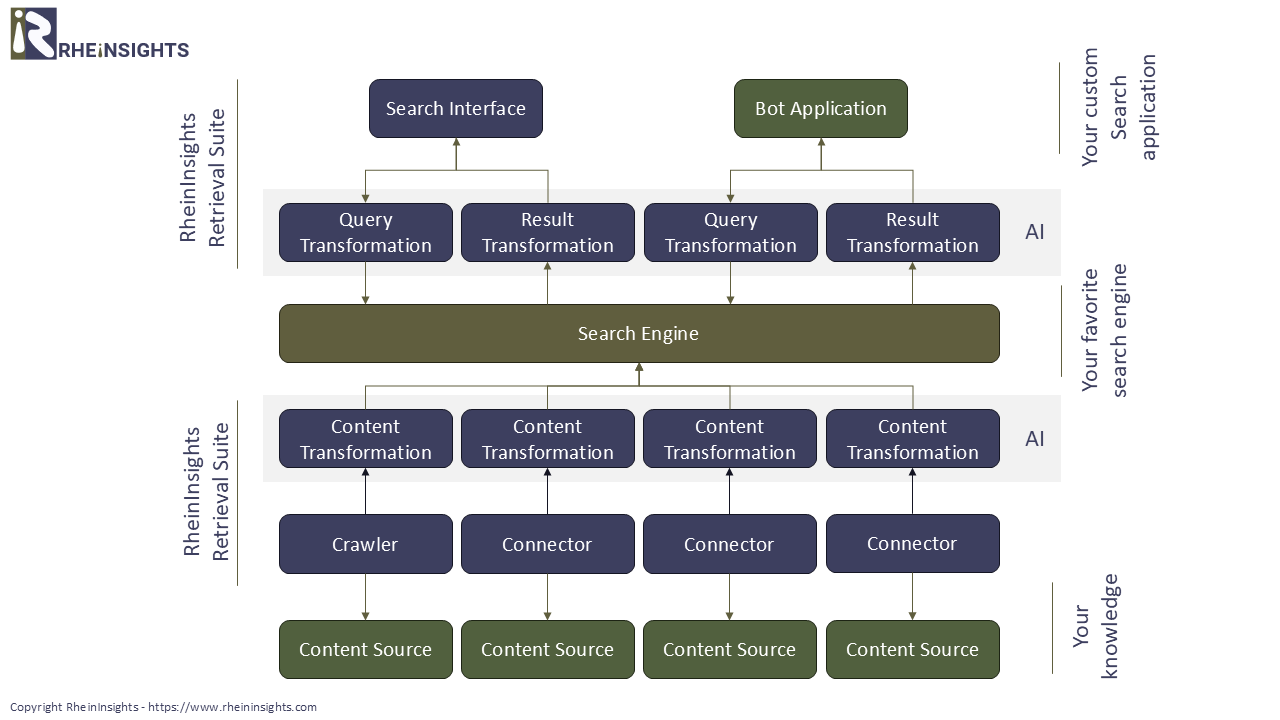
In this article we describe how you can use Azure AI Search to index the knowledge from Atlassian Confluence, make it searchable and also integrate it into a bot.
Indexing of Atlassian Confluence
To index Atlassian Confluence search connectors (or adapters) are generally used. In principle, it is possible to crawl Atlassian Confluence with a web crawler, especially in the server variants. However, a web crawler is not able to index access rights of pages and reaches its limits with OAuth. In turn, connectors in use the Confluence REST APIs, which allows for indexing page permissions. Before the Confluence content can be searched, it must be processed.
Document Processing in Azure AI Search
Within our blog post Document Processing in Azure AI Search we describe which options exist to transform documents in Azure AI Search. In general, we suggest the following processing steps for processing our Confluence content:
1. Document filter. As a first step, it makes sense to exclude all documents that do not provide any added value for a bot application from indexing. Document filters that filter images or videos, for example, are ideal for this purpose.
Additionally, there may be areas of the wiki that you do not want to indexed either. These can be excluded from crawling using a space filter.
2. Text extraction. As a next step, text extraction converts binary documents into text and removes HTML tags from e.g. web pages. Please refer e.g. to Documentation - Text Extractor for more information.
3. Document splitter. We always suggest that longish documents have to be separated into meaningful parts. This can be done at paragraph level or based on a maximum number of characters. Our document splitter recognizes paragraphs and achieves very good results, cf. e.g. Documentation - Document Splitter.
4. Vectorization. Even though Retrieval Augmented Generation delivers surprisingly good results with key phrase extraction applied at query time, it is common practice to use a vector search. So-called embeddings come into play at this point. Our Suite supports embeddings using OpenLlama or using Azure OpenAI. An embedding generates the vector representation of the (textual) document contents. Please refer to Documentation - Vectorizer.
Indexing
The result will then be indexed in Azure AI Search via REST APIs. The Steps 2, 3 and 4 above can be performed on Azure AI Search side, if an indexer along with a wizard are used.
Searching in Azure AI Search
As part of an Retrieval Augmented Generation, the user interacts with either a bot, a search application or a virtual agent. All of these can use intent recognition to decide whether a retrieval augmented generation should take place at all and, if so, which indices should be queried.
1. Query transformation. However, before the input actually triggers a search against the search index, it must be vectorized. Therefore, similar to the content transformation pipelines, so-called query pipelines (see, for example, Documentation - Query Pipeline) are used. These can either run outside of the AI Search instance or have been pre-configured using the AI Search Wizard.
2. Search. The transformed (vector-) query is then used to search and generate the result set.
3. Result Transformation. Now the search engine usually returns more than one hit. In any case all hits or just the first ones have to be transformed into a natural language output. This is where another Large Language Model comes into play. The hits are sent together with the query to the Completion API of the Large Language Model.
For example with the prompt:
A user asks the following question <QUERY>. The following results may contain answers [“Hit1”:”<HIT1>”,“Hit2”:”<HIT2>”,“Hit3”:”<HITS>”]. Answer the question based on these results. Be as precise as possible, do not create new information. Only use the information in the hits. If you can't answer the question, write "I don't know the answer."
Use cases for Retrieval Augmented Generation with Atlassian Confluence
As written above, many companies use Confluence as a vital knowledge management environment. Our customers therefore are regularly able to create knowledge applications for a wide variety of use cases. The following examples illustrate the added value.
Use Case 1. Classically, employees want help when using IT systems. Integration of knowledge from Confluence is therefore a very suitable approach as a “first-level support”. This can be offered, for example, next to the support form, or as a first step before a ticket can be opened.
Such a support bot can answer numerous user queries in advance. This can take place with high efficiency and without support being involved in the first place.
However, it is important to regularly check whether there are any questions which were not answered. If so, you need to check, if there is according knowledge and if this could also have been “found” by the bot. For example, (anonymized) search statistics can be used for this purpose.
In addition, when it comes to permissions (see Permission-Based Retrieval Augmented Generation (RAG)), care must be taken to ensure that content is published and visible to the user (as the bot impersonates as the user).
Use Case 2. As a second use case, we have a look at complex projects. Here regularly detailed questions cannot be cannot be easily answered by the embedded search. For example, how a certain module should work or how project teams should work together.
Here too, a knowledge search with a bot can provide information extremely efficiently. Atlassian Jira content can also be integrated into such a use case.
However, it should be noted that the bot should not only provide the answers, but always provide references, too. References enable searchers to identify relevant content.
Consistent Use of Embeddings
If a vector index is used, it is important that the search input is vectorized in the same way as the indexed documents. This means that the same embedding must be used in the content transformation as in the query transformation.
However, since different embeddings usually produce different vector dimensions, the search index and the dimensions of the vector fields force you to think about this.
Of course, there is an edge case. Trained models can generate different vectors with the same dimensions for the same documents. In such a rare case, “wrong” or irrelevant documents can be found.