Retrieval Augmented Generation mit Azure AI Search und Atlassian Confluence
10.2.2025
Atlassian Confluence überzeugt als Wiki und Collaboration-Plattform. Viele Organisationen nutzen es zur Erstellung von lebender Dokumentation (siehe bspw. Wikipedia). Also Dokumentation, die nicht nach einmaligem Niederschreiben seinem Schicksal übergeben wird, sondern immer wieder aktualisiert und auf Stand gehalten wird. Daher ist es eine wertvolle Quelle für Enterprise Search und Q&A-Bots.
Der Verarbeitungsprozess für Retrieval Augmented Generation ist in folgendem Diagramm skizziert.
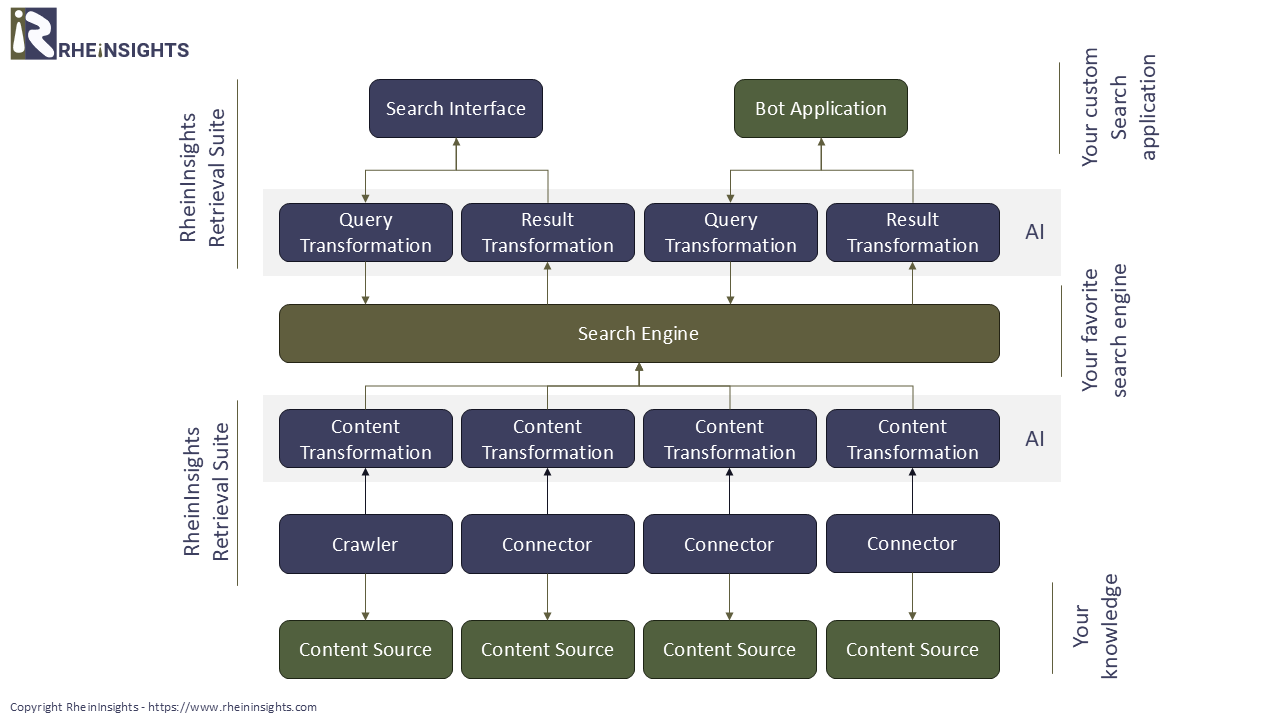
In diesem Artikel beschreiben wir, wie Sie mit Hilfe von Azure AI Search das Wissen aus Atlassian Confluence indexieren, es durchsuchbar machen und auch in einen Bot integrieren.
Indexierung von Atlassian Confluence
Zur Indexierung von Atlassian Confluence kommen grundsätzlich sogenannte Konnektoren (oder Adapter) zum Einsatz. Es ist zwar grundsätzlich möglich Atlassian Confluence zu crawlen insbesondere in den Server-Varianten. Ein Web-Crawler ist aber nicht in der Lage die Zugriffsrechte auf Seiten zu erfassen und stößt bei OAuth an seine Grenzen. Daher nutzen sogenannte Konnektoren die Confluence lieber die REST APIs, die ein Erfassen der Seiten, sowie der Seiten-Berechtigungen ermöglichen.
Bevor die Confluence-Inhalte aber an die Suche gehen, müssen Sie noch prozessiert werden.
Dokumentenverarbeitung in Azure AI Search
In unserem Blog Post Dokumentenverarbeitung für Azure AI Search zeigen wir auf, welche Optionen für eine Dokumentenverarbeitung in Azure AI Search existieren. Für die Verarbeitung unserer Confluence Inhalte schlagen wir an dieser Stelle die folgenden Verarbeitungsschritte vor:
1. Dokumentenfilter. Als erster Schritt ist es sinnvoll, sämtliche Dokumente, die keinen Mehrwert für eine Bot-Applikation liefern, vom Indexieren auszuschließen. Hierfür bieten sich Dokumentenfilter an, die beispielsweise Bilder oder Videos filtern.
Darüber hinaus, gibt es eventuell Bereiche im Wiki, die Sie gar nicht erst erfassen möchten. Diese kann man über einen Bereichs-Filter vom Crawling ausschließen.
2. Textextraktion. Danach wird eine Textextraktion angewandt, die binäre Dokumente in Text umwandelt und HTML-Tags aus Webseiten entfernt. Siehe Documentation - Text Extractor.
3. Dokument-Splitter. Wir schlagen immer vor, dass lange Dokumente in sinnvolle Untereinheiten getrennt werden. Dies kann auf Absatzebene geschehen oder anhand einer maximal-Anzahl von Zeichen. Unser Document Splitter erkennt Absätze und erzielt damit sehr gute Ergebnisse Documentation - Document Splitter.
4. Vectorisierung. Auch wenn Retrieval Augmented Generation mit einer Key-Phrase-Extraction auf Query-Ebene erstaunlich gute Ergebnisse liefert, ist es gang und gäbe eine Vektorsuche zu verwenden. Hierfür kommen sogenannte Embeddings in Frage. Unsere Suite unterstützt Embeddings mit Hilfe von OpenLlama oder mit Hilfe von Azure OpenAI. Siehe Documentation - Vectorizer.
Indexierung
Das Ergebnis wird dann in Azure AI Search per REST APIs indexiert werden. Hierbei können die Schritte 2., 3. und 4. auf Seiten Azure AI Search durchlaufen werden, wenn ein Indexer und ein Wizard verwendet werden.
Suche in Azure AI Search
Im Rahmen des Retrieval Augmented Generations interagiert der Nutzende entweder mit einem Bot, einer Suchapplikation oder einem anderen virtuellen Agenten. Dieser kann über eine Intent Recognition entscheiden, ob überhaupt ein Retrieval Augmented Generation stattfinden soll und wenn ja, welche Azure AI Search-Indizes angesprochen werden sollen.
1. Query Transformation. Bevor die Eingabe an den Suchindex geht, muss diese jedoch wieder vektorisiert werden. Daher kommen analog zu den Content Transformation Pipelines sogenannten Query Pipelines (siehe bspw. Documentation - Query Pipelines) zum Einsatz. Diese können entweder außerhalb der AI Search laufen, oder per AI Search Wizard vorab konfiguriert worden sein.
2. Result Transformation. Nun liefert die Suchmaschine aber in der Regel mehr als einen Treffer zurück und diese Treffer müssen nun zu einer natürlich-sprachigen Ausgabe transformiert werden. Hier kommt ein Large Language Model zum dritten Mal ins Spiel, aber in Form einer Completion. Die Treffer werden hierbei zusammen mit der Query an die Completion API des Large Language Model gegeben.
Beispielsweise mit dem Prompt:
Ein Benutzer stellt folgende Frage <QUERY>. Die folgenden Treffer können Antworten enthalten [“Treffer1”:”<TREFFER1>”,“Treffer2”:”<TREFFER2>”,“Treffer3”:”<TREFFER3>”]. Beantworte die Frage anhand dieser Treffer. Sei so präzise wie möglich, erzeuge keine neuen Informationen. Verwende nur die Informationen in den Treffern. Wenn du die Frage nicht beantworten kannst, schreibe “Ich kenne die Anwort nicht”.
Anwendungsfälle für Retrieval Augmented Generation mit Atlassian Confluence
Viele Unternehmen nutzen Confluence als lebende Wissensmanagement-Umgebung. Daher erstellen unsere Kunden regelmäßig Wissensapplikationen für unterschiedlichste Anwendungsfälle. Die folgenden Beispiele illustrieren den Mehrwert.
Use Case 1. Ganz klassisch möchten Mitarbeitende Hilfestellungen zu IT-Systemen. Als “First-Level-Support” eignet sich daher eine Integration des Wissens aus Confluence. Diese kann beispielsweise in der Nähe des Support-Formulars angeboten werden, oder als erster Schritt, bevor ein Ticker eröffnet werden kann.
Ein solcher Support-Bot kann zahlreiche Nutzeranfragen mit hoher Effizienz im Vorfeld beantworten, ohne dass der Support zunächst involviert wird.
Wichtig ist hierbei, dass regelmäßig überprüft wird, ob es überhaupt Inhalte gibt, die Nutzeranfragen, die die Frage beantwortet hätten und auch vom Bot hätten “gefunden” werden können. Hierfür können beispielsweise (anonymisierte) Suchstatistiken zum Einsatz kommen.
Zudem muss bei Berechtigungen (siehe Sicheres Retrieval Augmented Generation (RAG) mit Berechtigungen) darauf geachtet werden, dass Inhalte bspw. publiziert und für den Nutzer (als der sich der Bot impersoniert) sichtbar sind.
Use Case 2. Zudem gibt es in komplexen Projekten regelmäßig detaillierte Fragestellungen, die die Suche von Atlassian Confluence nicht ohne weiteres beantworten kann. Beispielsweise, wie ein bestimmtes Modul zu funktionieren hat oder wie Projektteams zusammen arbeiten sollen.
Auch hier kann eine Wissenssuche mit Bot äußerst effizient Informationen liefern. In einem solchen Use Case können auch Atlassian Jira-Inhalte integriert werden. Hierbei ist jedoch zu beachten, dass der Bot nicht allein die Antworten liefern sollte, sondern auch immer Referenzen angeben sollten. Referenzen ermöglichen den Suchenden relevante Inhalte zu erkennen.
Konsistenter Einsatz von Embeddings
Wenn ein Vektorindex zum Einsatz kommt, dann ist es wichtig, dass die Sucheingabe genauso vektorisiert wird, wie die indexierten Dokumente. Dies bedeutet, dass das gleiche Embedding in der Content Transformation und auch in der Query Transformation zum Einsatz kommen muss. Da aber in der Regel unterschiedliche Embeddings unterschiedliche Vektordimensionen erzeugen, zwingt einen der Suchindex und die Dimensionen der Vektorfelder hier zum Nachdenken.
Aber natürlich können trainierte Modelle bei gleichen Dokumenten unterschiedliche Vektoren mit den gleichen Dimensionen erzeugen. In einem solchen, seltenen Fall, können dann “falsche”, bzw. nicht relevante Dokumente gefunden werden.