Retrieval Augmented Generation in regulatorischen Berufen
März 2025
Retrieval Augmented Generation (RAG) und Enterprise Search können die Ausbildungskosten für Mitarbeiter in stark regulierten Bereichen deutlich senken. Dies gilt beispielsweise für Infrastrukturberufe wie im Bahn- oder Flugverkehr oder bei Telekomanbietern. Also dort, Disponenten und Administratoren zahlreiche Regeln und Vorschriften kennen und auch im Blick behalten müssen.
Welchen Vorteil bietet RAG-Anwendung, welche Zugriff auf Regularien und spezifische Gesetze bietet?
Natürlich müssen Auszubildende viele Konzepte auswendig lernen. Ein Q&A-Bot kann jedoch Fragen schnell und recht präzise beantworten. Insbesondere kann man ihn so aufsetzen, dass er die zugrunde liegenden Vorschriften auch zitiert. Selbst ungenaue Formulierungen lassen sich mit diesem Ansatz vom Bot beantworten. In der Summe reduziert eine solche Applikation die Ausbildungskosten, da sie Auszubildende weniger Zeit puzzlen und mehr Zeit für das Verstehen haben.
Large Language Models (LLMs) eignen sich bekanntlich hervorragend zur Bearbeitung rechtlicher Fragen. Natürlich gilt: Botapplikationen ersetzen niemals qualifizierte Kollegen oder Ausbildungsleiter. Sie sollten sich daher immer Rücksprache halten und mitdenken, anstatt blind den Anweisungen einer Suchmaschine zu folgen.
Einrichten einer RAG-Umgebung
Eine Retrieval Augmented Generation-Umgebung umfasst immer eine Suchmaschine (Retrieval), indexierte Daten, ein großes Sprachmodell und eine Benutzeroberfläche.
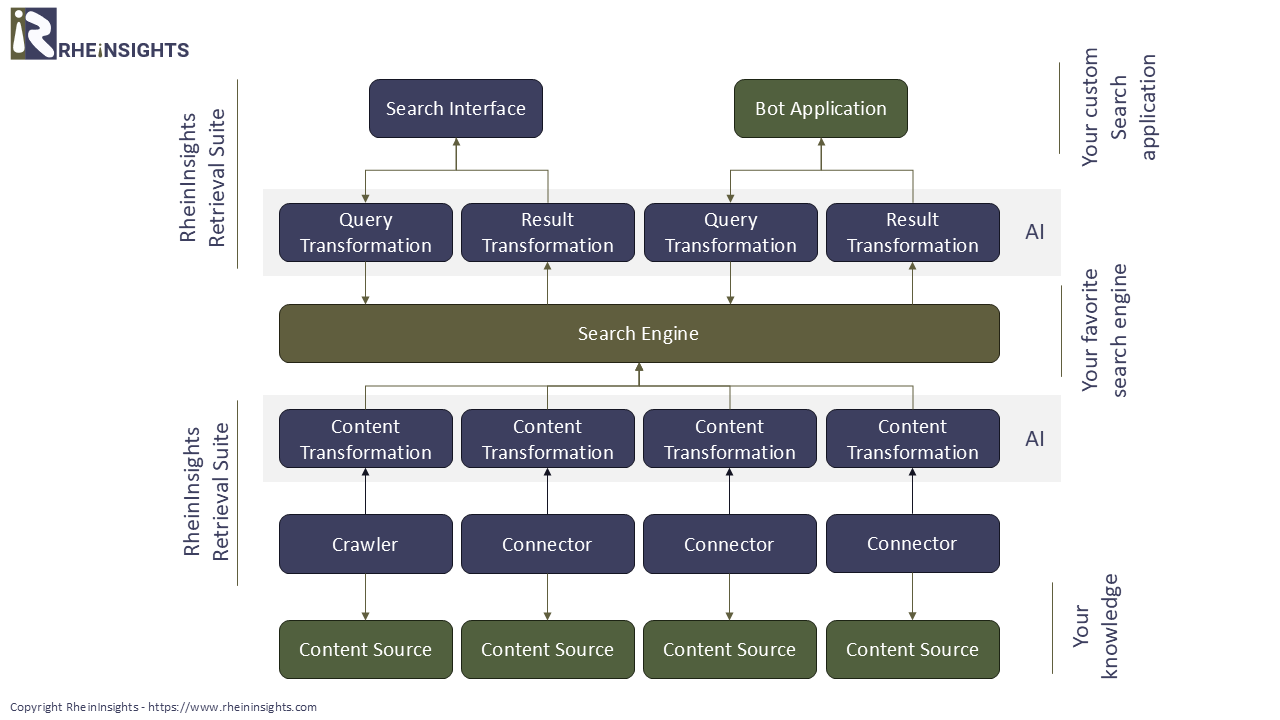
Das Einrichten der Umgebung bedeutet, dass Sie sich für eine (Vektor-)Suchmaschine entscheiden, diese bereitstellen und konfigurieren müssen.
Cloud-Suchmaschinen wie Azure AI Search sind als Managed Service verfügbar und ermöglichen einen einfachen Einstieg, ohne dass Sie Hardware einrichten und die Suchmaschine selbst deployen müssen. Andererseits kann eine On-Premise-Suchmaschine kostengünstiger sein.Sie müssen sich dann für Large Language Models für Embeddings und Completions entscheiden. Die sogenannten Embeddings sind dafür da, eine Transformation Ihres Textes in Vektoren durchzuführen. Die Completions werden verwendet um Antworten zu erzeugen (siehe unten).
Wir nutzen regelmäßig OpenAI GPT oder Open-Source-Modelle. Zum Beispiel nutzen wir das Model textembedding-ada-02 für die Vektorisierung und gpt-4o-mini für Completions.
Anschließend müssen die Daten indexiert werden. Dazu ist in der Regel das Crawlen eines File Shares, eines Enterprise Content Systems, wie SharePoint, oder von Webseiten nötig. Dies übernimmt ein Connector oder Crawler.
Bevor die Dokumente an die Suchmaschine, bzw. die Vektorisierung weitergeleitet werden, müssen Texte und Kontexte extrahiert werden. Hierfür bietet sich Apache Tika an, um Binärdokumente (z.B. PDFs oder Word-Dokumente) in Klartext umzuwandeln. Zudem empfehlen wir normalerweise, das Dokument in kleinere Abschnitte aufzuteilen, da dadurch die Relevanz viel besser und die Antworten präziser werden.
Zu guter Letzt müssen Sie den Dokumentinhalt mithilfe Ihres Embeddings vektorisieren.
Diese Vektoren können dann in der Suche indexiert werden.
Regulatorische Dokumente liegen in der Regel als umfangreiche PDF-Dateien oder PDF-Reihen vor. Manchmal sind sie auch auf Webseiten gespeichert. Durch die richtige Konfiguration Ihres Crawlers in ab Schritt 3 können Sie dann alle geltenden Gesetze und Vorschriften in Ihrer Suchmaschine indexieren.
Abrufen von Antworten basierend den indexierten Vorschriften
Jetzt haben Sie alle Ihre Dokumente in Ihrer Vektorsuche. Sie müssen dieses Wissen nur noch Ihren Benutzern zugänglich machen. Dazu müssen Sie den das User Interface als Teil Ihrer RAG-Anwendung entwickeln oder konfigurieren. Dies funktioniert wie folgt.
Erstellen Sie einen kleinen REST-Service, der Benutzeranfragen oder Fragen entgegennimmt
Die Benutzereingaben müssen ebenfalls vektorisiert werden. Hierbei muss dasselbe Embedding-Modell wie in Schritt 6 oben verwendet werden
Dann können Sie die Suchmaschine mit diesem Vektor als Suchquery abfragen
Die Suchmaschine liefert Ergebnisse und diese Suchergebnisse werden zusammen mit der Nutzeranfrage an die Completion-API Ihres Sprachmodells weitergeleitet.
Zum Beispiel wie folgt:„Ein Nutzer stellt die folgende Frage: ‚<Frage>‘. Hier sind passende Suchtreffer: ‚<Suchergebnis1>‘, ‚<Suchergebnis2>‘, ‚<Suchergebnis3>‘. Kannst du die Frage anhand dieser Ergebnisse beantworten?
Diese Abfrage wird dann an die Completions-API Ihres Sprachmodells weitergeleitet.
Geben Sie anschließend das Ergebnis als Response Ihrer REST-API zurück.
Sie können eine solche REST-API in Teams, in Slack oder auf einer Webseite integrieren – überall dort, wo Ihre Benutzer und Auszubildenden nach Regularien Fragen und Antworten benötigen.
Unser Produkt - die RheinInsights Retrieval Suite
Wie oben beschrieben, können Sie ganz einfach eine Q&A-Anwendung für Gesetzestexte und Regularien erstellen. Der Vorteil der RheinInsights Retrieval Suite besteht darin, dass sie einerseits das Erfassen (Crawlen der Dokumente), Textextraktion, Dokumenten-Splitting und Vektorisierung vereint. Zudem bietet sie ein umfangreiches Suchinterface und REST-APIs.
Auf diesem Wege können Sie mit wenigen Klicks Ihre Regularien in Ihre Suchmaschine indexieren und ein Interface Ihren Nutzern verfügbar machen. Das alles während Sie die volle Kontrolle über die zugrunde liegenden Daten und die Suchmaschine behalten.